사용자 학습 패턴 분석
사용자 학습 패턴 분석
사용자의 퀴즈 풀이 패턴을 더 깊이 있게 분석하고 맞춤형 피드백을 제공하기 위해 기능 업데이트를 진행했다.
단순히 “맞았다/틀렸다”를 넘어
사용자가 어떤 유형(문법/어휘)에서 약한지, 빈칸을 채우는 데 몇 초가 걸렸는지, 어떤 오답을 적었는지 파악할 수 있다.
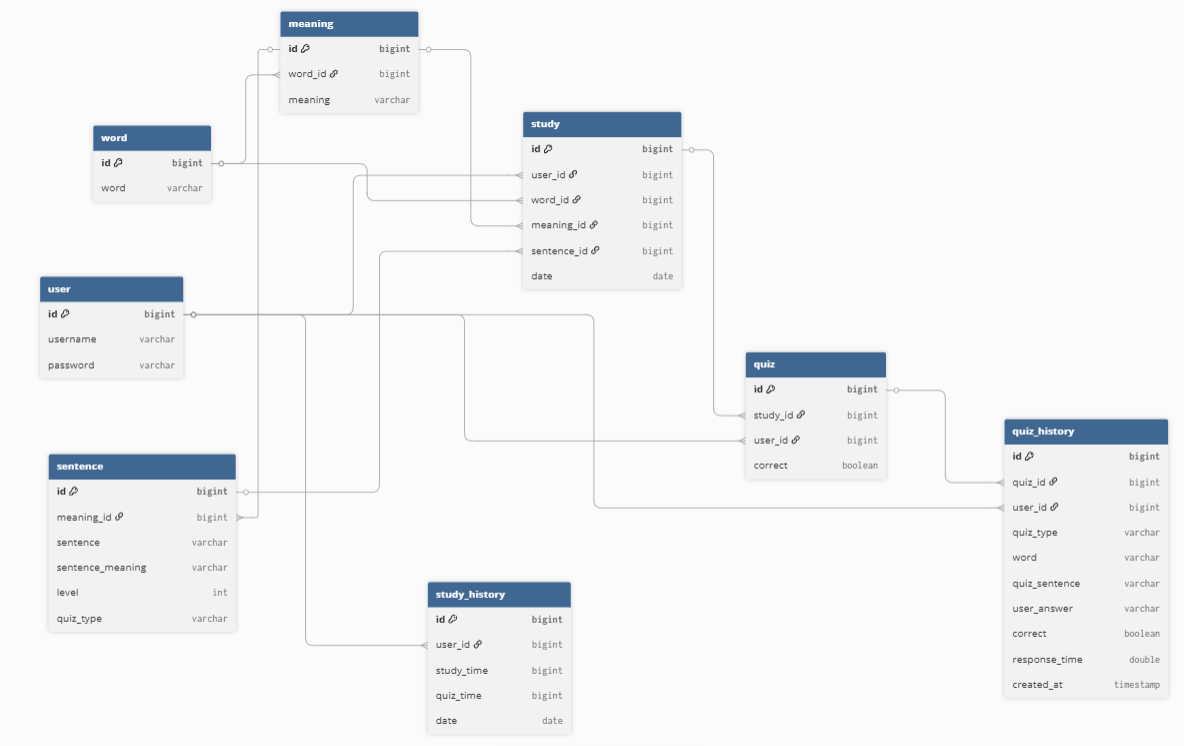
1. DB 설계
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
CREATE TABLE `quiz_history` (
`id` BIGINT NOT NULL AUTO_INCREMENT,
`quiz_id` BIGINT NOT NULL,
`user_id` BIGINT NOT NULL,
`quiz_type` VARCHAR(255) NOT NULL COMMENT '퀴즈 유형 (문법, 어휘 등)',
`word` VARCHAR(255) COMMENT '단어',
`quiz_sentence` VARCHAR(255) COMMENT '빈칸이 있는 퀴즈 문장',
`user_answer` VARCHAR(255) COMMENT '사용자가 제출한 정답/오답 텍스트',
`correct` BOOLEAN NOT NULL COMMENT '그 당시에 맞았는지 틀렸는지 여부 (Boolean)',
`response_time` DOUBLE NOT NULL COMMENT '문제 풀이 시간',
`created_at` TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
CONSTRAINT `fk_quiz_history_quiz` FOREIGN KEY (`quiz_id`) REFERENCES `quiz` (`id`) ON DELETE CASCADE,
CONSTRAINT `fk_quiz_history_user` FOREIGN KEY (`user_id`) REFERENCES `user` (`id`) ON DELETE CASCADE
)
*백틱 생략 가능
quiz_history를 추가한 이유
기존에는 quiz 테이블에서 정답 여부(correct)만 상태 값으로 업데이트하는 구조였다.
처음에는 상태 업데이트 방식을 활용하려 했으나 이 방식으로는 사용자의 성장 과정을 추적할 수 없어
매 퀴즈 시도마다 데이터를 쌓는 quiz_history 테이블을 새로 만들게 되었다.
1차 시도: 10초 소요, “apples” 작성 (오답) 👉
quiz_history에 기록,quiz는correct=false2차 시도: 5초 소요, “apple” 작성 (정답) 👉
quiz_history에 기록,quiz는correct=true
과거 오답 로그가 그대로 보존되므로
“처음엔 10초 걸려 틀렸지만, 다시 풀었을 땐 5초 만에 맞혔다”는 식의 학습 성장 그래프의 데이터를 만들 수 있다.
sentence 테이블과 quiz_history에 quiz_type(문법/어휘) 컬럼을 추가해
이후에 유저가 취약한 문제 유형을 통계 낼 수 있도록 구성할 수 있다.
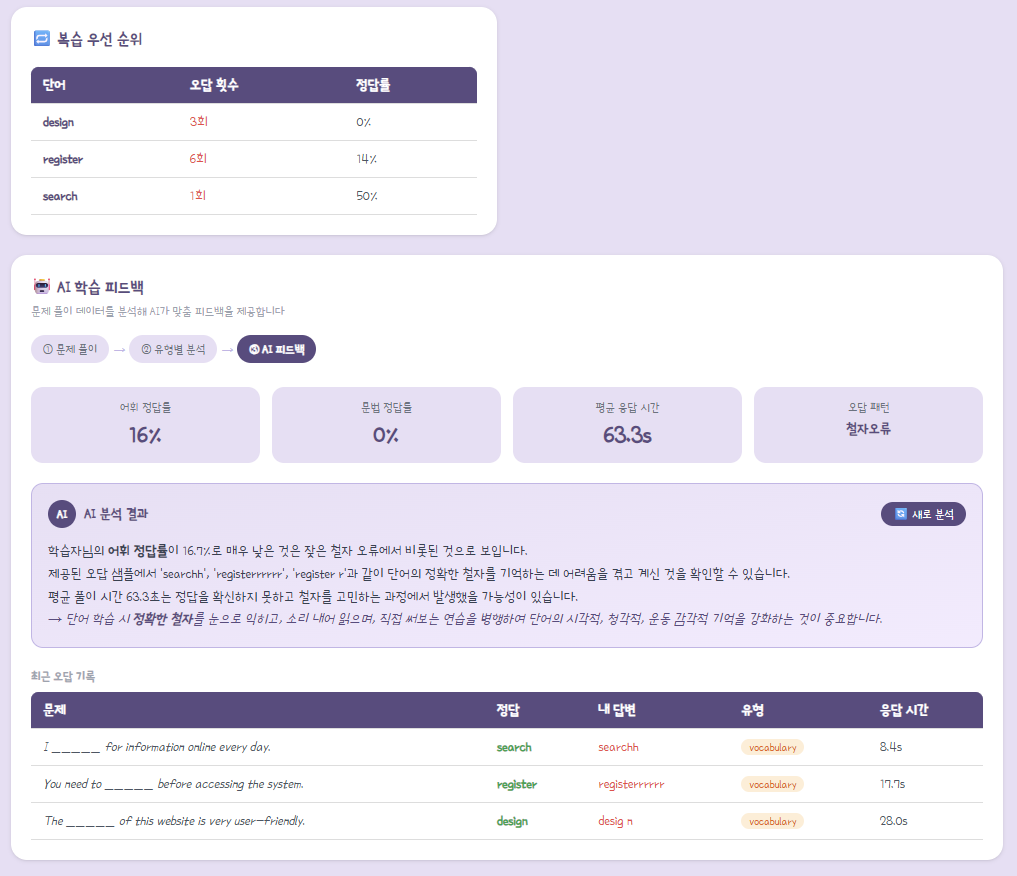
2. 마이페이지 화면 구성: AI 분석 기반 3대 위젯
적재된 데이터를 바탕으로 마이페이지에 피드백을 제공하는 3가지 기능을 구현했다.
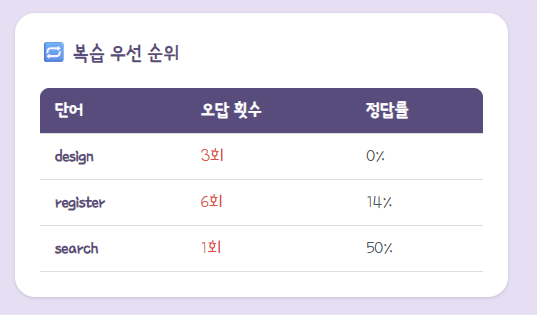
- 우선순위 복습 단어 Top 3:
- 단순히 틀린 횟수만 보지 않고 (오답 횟수 * 0.6) + (오답률 * 0.4) 의 가중치 공식을 적용하여 복습이 시급한 단어 3개를 추출한다.
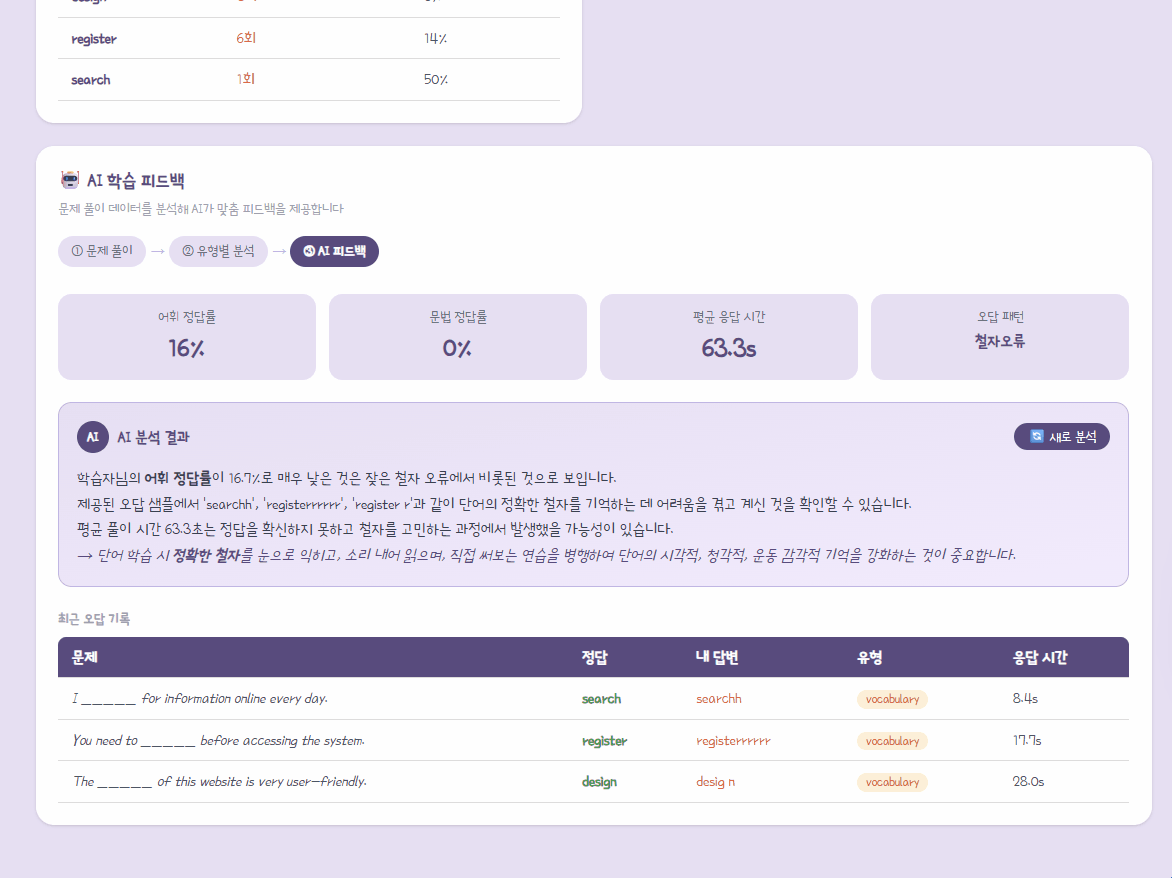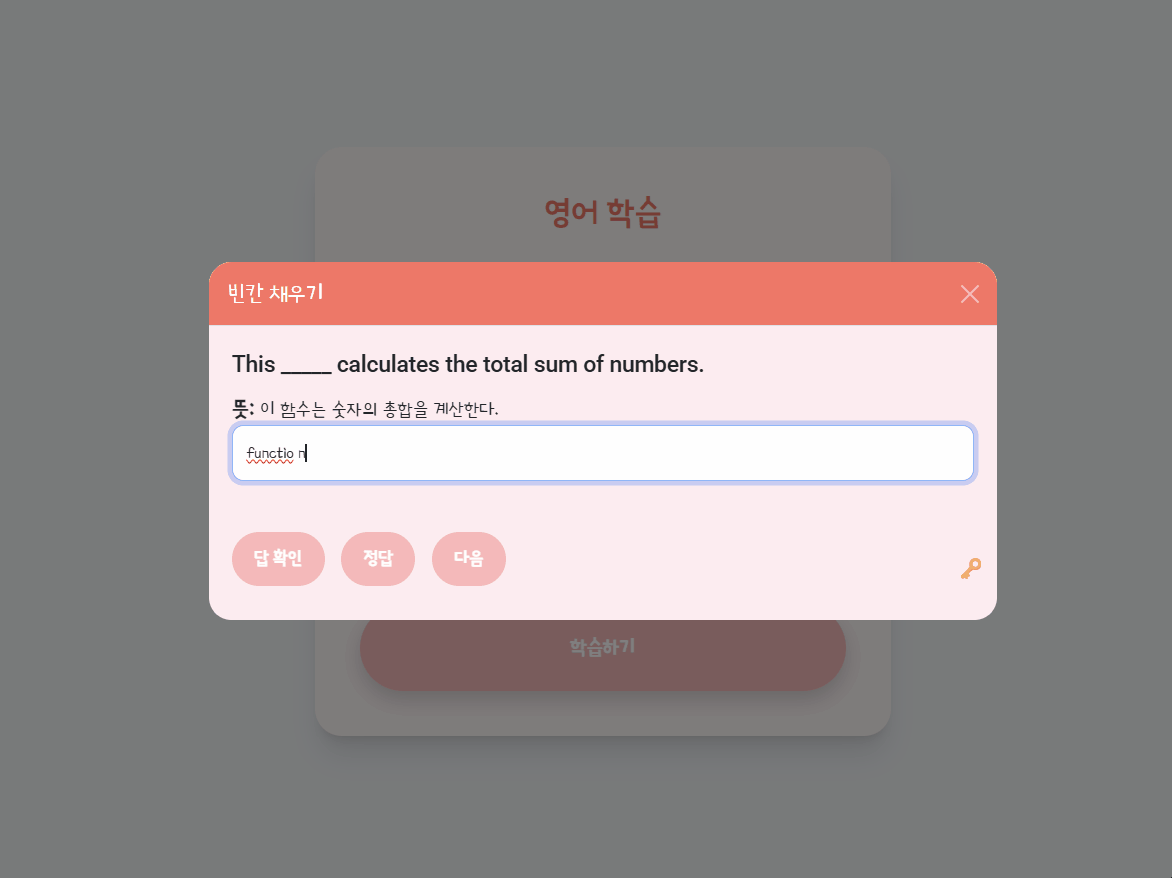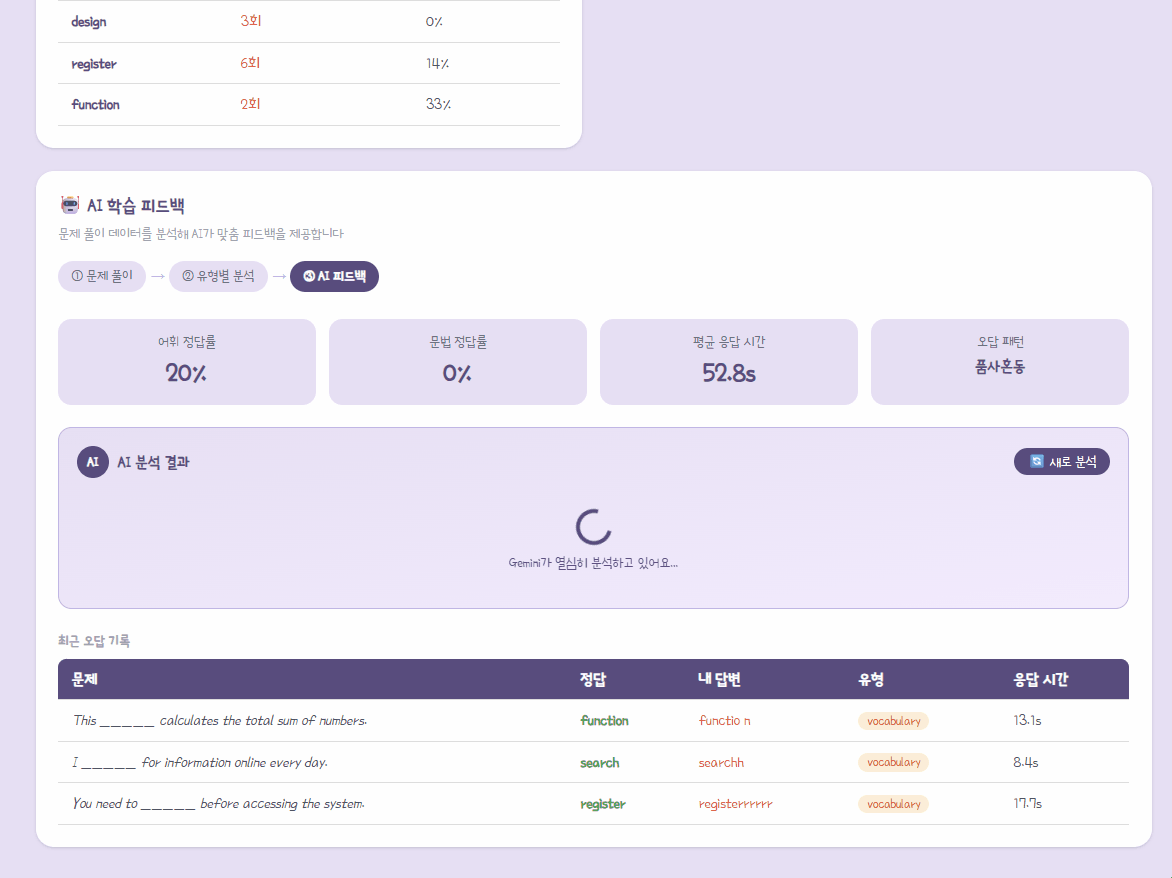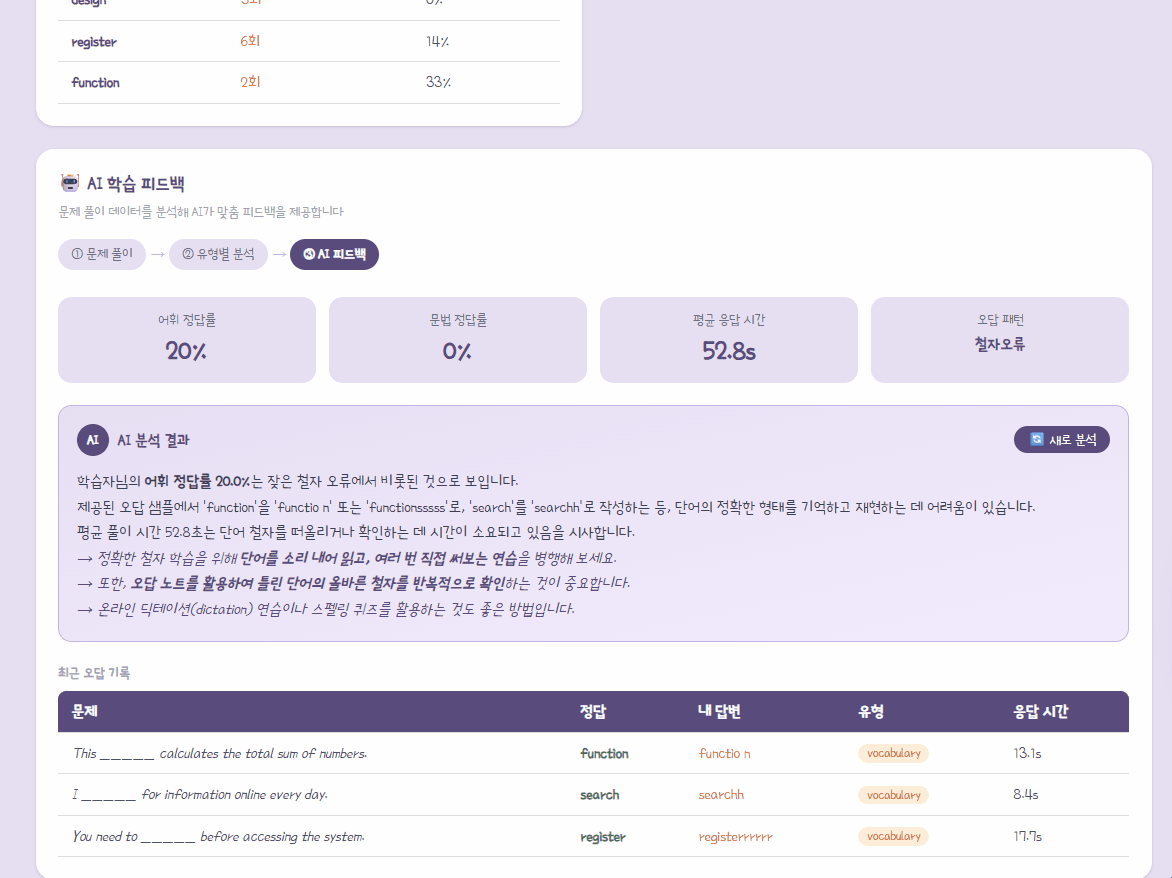
- AI 학습 통계 보드:
- 전체 시도 대비 어휘/문법 퀴즈 정답률, 그리고 평균 문제 풀이 시간(초)을 계산하여 보여준다.

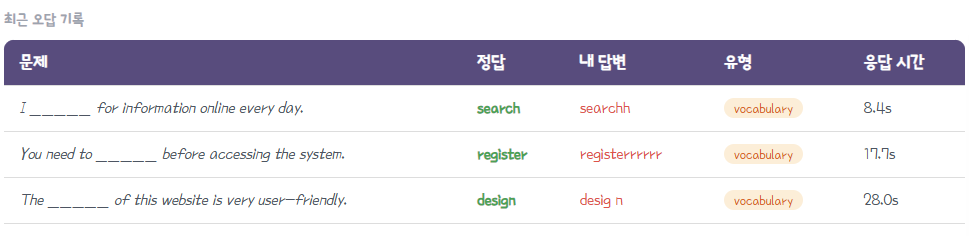
- 최근 오답 기록 로그:
- 최근 틀린 문장, 정답 단어, 사용자가 제출한 오답, 소요 시간, 퀴즈 유형(색상 구분)을 리스트업하여 보여준다.
3. 트러블슈팅: Spring Data JPA Native Query와 DTO 매핑 이슈
복습 우선순위 Top 3를 뽑기 위해 내부에서 가중치를 계산하여 LIMIT 3으로 가져오는 로직을 작성했다.
LIMIT 구문 사용을 위해 JPQL 대신 Native Query를 선택했는데 여기서 에러가 발생했다.
문제
1
No converter found capable of converting from type [org.springframework.data.jpa.repository.query.AbstractJpaQuery$TupleConverter$TupleBackedMap] to type [com.eng.dto.QuizHistoryResponseDto]
원인
네이티브 쿼리는 MySQL 엔진이 직접 실행한다.
SELECT 절에 new com.eng.dto.QuizHistoryResponseDto(...) 같은 패키지 경로를 포함한
객체 생성 표현식을 쓰면 DB가 이를 이해하지 못해 Syntax 에러를 뱉어낸다.
*해당 객체를 사용하지 않아도 오류가 떴다.
✅ 해결: Interface 기반 Projections 사용
DTO 대신 쿼리 결과의 별칭(AS)과 매칭되는 Getter 메서드를 가진 인터페이스(Interface)를 선언하여 매핑 문제를 해결했다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
// 1. Interface 정의
public interface RepeatWordMapping {
String getWord();
Long getWrongCount();
Double getCorrectRate();
}
// 2. Repository 쿼리 수정
@Query(nativeQuery = true, value =
"SELECT " +
" word AS word, " +
" SUM(CASE WHEN correct = false THEN 1 ELSE 0 END) AS wrongCount, " +
" (SUM(CASE WHEN correct = true THEN 1 ELSE 0 END) / COUNT(*)) * 100 AS correctRate " +
"FROM quiz_history " +
"WHERE user_id = :userId " +
"GROUP BY word " +
"ORDER BY (SUM(CASE WHEN correct = true THEN 1 ELSE 0 END) * 0.6) " +
" + ((100 - (SUM(CASE WHEN correct = true THEN 1 ELSE 0 END) / COUNT(*)) * 100) * 0.4) DESC " +
"LIMIT 3")
List<RepeatWordMapping> getReview(Long userId);
4. 로컬 테스트 환경 세팅: 데이터 초기화와 캐시 비우기
문제 10개, 학습 10개로 제한을 둔 상태였기 때문에 반복 테스트하기 위해 기존 데이터를 삭제해야했다.
4.1 RDBMS (MySQL) 초기화
테이블 간 외래키(Foreign Key)가 얽혀있어 TRUNCATE가 제대로 실행되지 않았다.
다음과 같이 제약 조건을 임시 해제하여 초기화했다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
-- 1. 안전을 위해 외래키 제약 조건 잠시 끄기
SET FOREIGN_KEY_CHECKS = 0;
-- 2. 각 테이블 데이터 전면 초기화
TRUNCATE TABLE quiz_history;
TRUNCATE TABLE quiz;
TRUNCATE TABLE study_history;
TRUNCATE TABLE study;
TRUNCATE TABLE sentence;
TRUNCATE TABLE meaning;
TRUNCATE TABLE word;
-- 3. 외래키 제약 조건 다시 켜기 (필수)
SET FOREIGN_KEY_CHECKS = 1;
4.2 Redis 캐시 초기화
DB를 날렸음에도 퀴즈 문제를 풀 수가 없어 Redis의 캐시데이터도 제거했다.
1
2
3
4
5
# 캐시 완전히 비우기
docker exec -it <컨테이너_이름_또는_ID> redis-cli flushall
# 비워졌는지 확인하기 (0이 나오면 정상)
docker exec -it <컨테이너_이름_또는_ID> redis-cli dbsize
5. AI
Gemini-API를 활용했다.
공식 문서를 참고해 작성했다.
5.1 AI 적용하기
1
2
3
4
5
6
# build.gradle
implementation platform("org.springframework.ai:spring-ai-bom:1.1.7")
implementation "org.springframework.ai:spring-ai-starter-model-google-genai"
# application.properties
spring.ai.google.genai.api-key=
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
public AiFeedbackResponseDto getAiFeedback(String username) {
try {
User user = userRepository.findByUsername(username).orElseThrow(UserNotFoundException::new);
AiMappingInterface aiData = quizHistoryRepository.getAiData(user.getId());
List<QuizHistory> wrongSamples = quizHistoryRepository.findTop3ByUserIdAndCorrectFalseOrderByIdDesc(user.getId());
StringBuilder wrongText = new StringBuilder();
for (QuizHistory q : wrongSamples) {
wrongText.append(String.format("- 문제: %s (원래정답: %s / 사용자오답: %s)\n",
q.getQuizSentence(), q.getWord(), q.getUserAnswer()));
}
String instruction = String.format(
"당신은 전문적인 영어 교육 AI 튜터입니다. 아래 제공된 학습자의 통계와 오답 샘플을 바탕으로 정밀 진단을 내리세요.\n\n" +
"[학습자 통계]\n" +
"- 어휘 정답률: %.1f%% / 문법 정답률: %.1f%% / 평균 풀이 시간: %.1f초\n\n" +
"[최근 오답 샘플]\n" +
"%s\n" +
"[작성 규칙]\n" +
"★중요: 결과는 반드시 '오답패턴 요약 : 피드백 문장' 구조로만 시작해야 합니다. 패턴 요약과 피드백 사이의 ' : ' 기호를 절대 생략하거나 줄바꿈하지 마세요.\n" +
"1. '오답패턴 요약'은 가장 두드러지는 핵심 취약점을 10자 이내의 단어로 요약하세요. (예: 품사혼동, 시제오류, 철자오류 등)\n" +
"2. '피드백 문장'은 통계 수치와 오답 문장을 융합하여 취약한 부분과 솔루션을 친절하게 HTML 형식으로 작성하세요.\n" +
" - 핵심구문은 <strong> 태그를 사용하세요.\n" +
" - 실천가이드는 시작할 때 줄을 바꾸고 <em style='color:#5A4B81'>→ ...</em> 태그를 조합하세요.\n" +
" - ★[중요] 가독성을 위해 각 문장이 끝나는 온점(.) 뒤에는 문자 '\\n' 대신 반드시 HTML 줄바꿈 태그인 '<br>'을 붙여서 한 줄씩 줄바꿈을 해주세요.\n\n" +
"[출력 예시]\n" +
"철자오류 : 학습자님의 <strong>어휘 정답률</strong>은 잦은 철자 오류에서 비롯된 것으로 보입니다.<br>단어의 정확한 형태를 기억하는 데 어려움이 있습니다.<br><em style='color:#5A4B81'>→ 연습을 병행해 보세요.</em>",
aiData.getVocabularyCorrectRate(), aiData.getGrammarCorrectRate(), aiData.getAvgResponseTime(), wrongText.toString()
);
ChatResponse response = chatModel.call(
new Prompt(
instruction,
GoogleGenAiChatOptions.builder()
.model("gemini-2.5-flash")
.temperature(0.3)
.build()
)
);
String responseText = response.getResult().getOutput().getText().trim();
String[] parts = responseText.split(" : ", 2);
String errorPattern = parts.length > 0 ? parts[0] : "분석 완료";
String aiFeedback = parts.length > 1 ? parts[1] : responseText;
return AiFeedbackResponseDto.builder()
.errorPattern(errorPattern)
.aiFeedback(aiFeedback)
.build();
} catch (Exception e) {
e.printStackTrace();
return AiFeedbackResponseDto.builder()
.errorPattern("분석 지연")
.aiFeedback("현재 분석 로딩이 원활하지 않습니다. 잠시 후 <strong>[새로 분석]</strong>을 시도해주세요.")
.build();
}
}
TOKEN 이슈로 raw data를 ai에게 전달해주는 대신 일부 데이터를 정리해서 ai에게 분석하게 설정했다.
5.2 AI Feedback db 저장하기
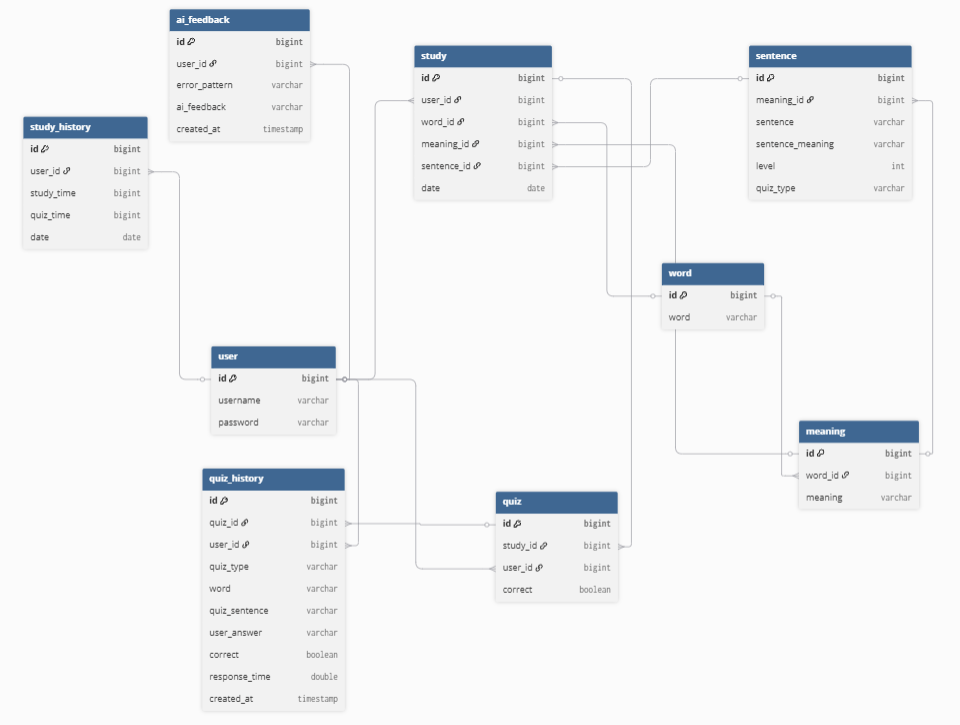
페이지가 로드될 때마다 AI를 활용해 분석을 시도 했다가 피드백을 받은 내용들을 DB에 저장하여
우선적으로 DB에 나온것을 적어주고 새로고침 시에 새로운 피드백을 받는 것으로 변경했다.
1
2
3
4
5
6
7
8
9
10
CREATE TABLE ai_feedback (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
user_id BIGINT NOT NULL,
error_pattern VARCHAR(255) NOT NULL,
ai_feedback VARCHAR(1000) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
CONSTRAINT fk_ai_feedback_user
FOREIGN KEY (user_id) REFERENCES user (id) ON DELETE CASCADE
);
1
2
3
4
5
6
7
8
9
10
11
public AiFeedbackResponseDto getAiFeedback(String username) {
User user = userRepository.findByUsername(username).orElseThrow(UserNotFoundException::new);
AiFeedback feedback = aiFeedbackRepository.findTopByUserIdOrderByCreatedAtDesc(user.getId());
if(feedback==null){
return getRefreshFeedback(username);
}
return AiFeedbackResponseDto.builder()
.aiFeedback(feedback.getAiFeedback())
.errorPattern(feedback.getErrorPattern())
.build();
}