code
단일 연결 리스트
데이터와 다른 노드를 가리킬 주소 데이터를 담을 객체가 필요하다. → 노드(node)
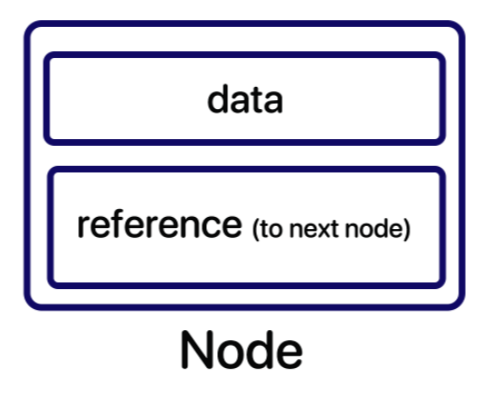
사용자가 저장할 데이터는 data 변수에 담기고, reference 데이터(참조 데이터)는 다음에 연결할 노드를 가리키는 데이터가 담긴다.
위와같은 노드들이 여러개가 연결 되어있는 것을 연결 리스트, 즉 LinkedList라고 한다.
이렇게 연결된 노드들에서 ‘삽입‘을 한다면 링크만 바꿔주면 되기 때문에 매우 편리하며,
반대로 ‘삭제‘를 한다면 삭제 할 노드에 연결 된 이전노드에서 링크를 끊고 삭제할 노드의 다음 노드를 연결해주면 된다.
Node 구현
가장 기본적인 데이터를 담을 Node 클래스를 먼저 구현해줘야한다.
1
2
3
4
5
6
7
8
9
10
class Node<E> {
E data;
Node<E> next; // 다음 노드객체를 가리키는 래퍼런스 변수
Node(E data) {
this.data = data;
this.next = null;
}
}
next 가 앞서 그림에서 보여주었던 Reference 변수다.
다음 노드를 가리키는 변수이며, ‘노드 자체’를 가리키기 때문에 타입 또한 Node<E>타입으로 지정해주어야 한다.
그리고 위 노드를 이용하기 위한 단일 연결리스트(Singly LinkedList)를 구현하면 된다.
List Interface
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
public interface List<E> {
boolean add(E value);
void add(int index, E value);
E remove(int index);
boolean remove(Object value);
E get(int index);
void set(int index, E value);
boolean contains(Object value);
int indexOf(Object value);
int size();
boolean isEmpty();
public void clear();
}
boolean add(E value);- 리스트에 요소를 추가한다.
- @param : value 리스트에 추가할 요소
- @return : 리스트에서 중복을 허용하지 않을 경우에 리스트에 이미 중복되는
요소가 있을 경우 {@code false}를 반환하고, 중복되는 원소가 없을경우 {@code true}를 반환
void add(int index, E value);- 리스트에 요소를 특정 위치에 추가한다.
- 특정 위치 및 이후의 요소들은 한 칸씩 뒤로 밀린다.
- @param : index 리스트에 요소를 추가할 특정 위치 변수
- @param : value 리스트에 추가할 요소
E remove(int index);- 리스트의 index 위치에 있는 요소를 삭제한다.
- @param : index 리스트에서 삭제 할 위치 변수
- @return : 삭제된 요소를 반환
boolean remove(Object value);- 리스트에서 특정 요소를 삭제합니다. 동일한 요소가 여러 개일 경우 가장 처음 발견한 요소만 삭제된다.
- @param : value 리스트에서 삭제할 요소
- @return : 리스트에 삭제할 요소가 없거나 삭제에 실패할 경우 {@code false}를 반환하고 삭제에 성공할 경우 {@code true}를 반환
E get(int index);- 리스트에 있는 특정 위치의 요소를 반환한다.
- @param : index 리스트에 접근할 위치 변수
- @return : 리스트의 index 위치에 있는 요소 반환
void set(int index, E value);- 리스트에서 특정 위치에 있는 요소를 새 요소로 대체한다.
- @param : index 리스트에 접근할 위치 변수
- @param : value 새로 대체할 요소 변수
boolean contains(Object value);- 리스트에 특정 요소가 리스트에 있는지 여부를 확인한다.
- @param : value 리스트에서 찾을 특정 요소 변수
- @return : 리스트에 특정 요소가 존재할 경우 {@code true}, 존재하지 않을 경우 {@code false}를 반환
int indexOf(Object value);- 리스트에 특정 요소가 몇 번째 위치에 있는지를 반환한다.
- @param : value 리스트에서 위치를 찾을 요소 변수
- @return : 리스트에서 처음으로 요소와 일치하는 위치를 반환, 만약 일치하는 요소가 없을경우 -1 을 반환
int size();- 리스트에 있는 요소의 개수를 반환
- @return : 리스트에 있는 요소 개수를 반환
boolean isEmpty();- 리스트에 요소가 비어있는지를 반환한다.
- @return : 리스트에 요소가 없을경우 {@code true}, 요소가 있을경우 {@code false}를 반환
public void clear();- 리스트에 있는 요소를 모두 삭제한다.
SingleLinked 클래스
List 인터페이스를 implements 해준다.
1
2
3
4
5
6
7
8
9
10
11
12
public class SingleLinked<E> implements List<E> {
private Node<E> head; // 노드의 첫 부분
private Node<E> tail; // 노드의 마지막 부분
private int size; // 요소 개수
// 생성자
public SingleLinked() {
this.head = null;
this.tail = null;
this.size = 0;
}
}
Node
head : 리스트의 가장 첫 노드를 가리키는 변수다. Node
tail : 리스트의 가장 마지막 노드를 가리키는 변수다. size : 리스트에 있는 요소의 개수(=연결 된 노드의 개수)
처음 단일 연결리스트를 생성 할 때에는 아무런 데이터가 없으므로
head와 tail이 가리킬 노드가 없기에 null로 초기화 및 size는 0으로 초기화해준다.
search 메소드 구현
단일 연결리스트이다보니 특정 위치의 데이터를 삽입, 삭제, 검색하기 위해서는
처음 노드(head)부터 next변수를 통해 특정 위치까지 찾아가야 하기 때문에 search() 메소드를 작성한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// 특정 위치의 노드를 반환하는 메소드
private Node<E> search(int index) {
// 범위 밖(잘못된 위치)일 경우 예외 던지기
if(index < 0 || index >= size) {
throw new IndexOutOfBoundsException();
}
Node<E> x = head; // head가 기리키는 노드부터 시작
for (int i = 0; i < index; i++) {
x = x.next; // x노드의 다음 노드를 x에 저장한다
}
return x;
}
add 메소드 구현
가장 앞부분에 추가 - addFirst(E value)
가장 마지막 부분에 추가 (기본값) - addLast(E value)
특정 위치에 추가 - add(int index, E value)
addFirst(E value) : 가장 앞부분에 추가
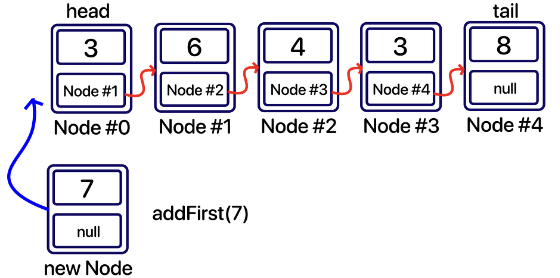
1
2
3
4
5
6
7
8
9
10
11
public void addFirst(E value) {
Node<E> newNode = new Node<E>(value); // 새 노드 생성
newNode.next = head; // 새 노드의 다음 노드로 head 노드를 연결
head = newNode; // head가 가리키는 노드를 새 노드로 변경
size++;
if (head.next == null) {
tail = head;
}
}
if (head.next == null) {tail = head;}
다음에 가리킬 노드가 없는 경우(=데이터가 새 노드밖에 없는 경우)
데이터가 한 개(새 노드)밖에 없으므로 새 노드는 처음 시작노드이자 마지막 노드다.
즉 tail = head 다.
addLast(E value) : 가장 마지막 부분에 추가
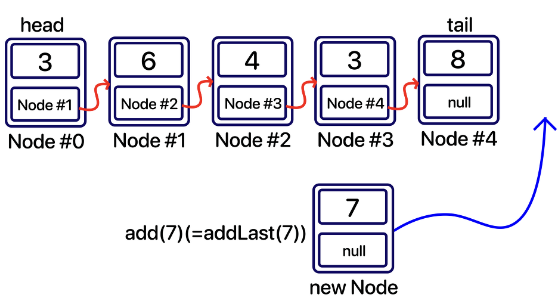
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
public boolean add(E value) {
addLast(value);
return true;
}
public void addLast(E value) {
Node<E> newNode = new Node<E>(value); // 새 노드 생성
if (size == 0) { // 처음 넣는 노드일 경우 addFisrt로 추가
addFirst(value);
return;
}
// 마지막 노드(tail)의 다음 노드(next)가 새 노드를 가리키도록 하고
// tail이 가리키는 노드를 새 노드로 바꿔준다.
tail.next = newNode;
tail = newNode;
size++;
}
add(int index, E value) : 특정 위치에 추가
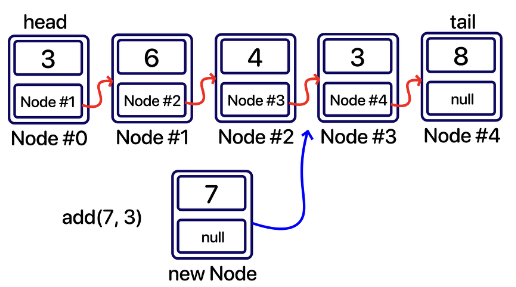
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
@Override
public void add(int index, E value) {
// 잘못된 인덱스를 참조할 경우 예외 발생
if (index > size || index < 0) {
throw new IndexOutOfBoundsException();
}
// 추가하려는 index가 가장 앞에 추가하려는 경우 addFirst 호출
if (index == 0) {
addFirst(value);
return;
}
// 추가하려는 index가 마지막 위치일 경우 addLast 호출
if (index == size) {
addLast(value);
return;
}
// 추가하려는 위치의 이전 노드
Node<E> prev_Node = search(index - 1);
// 추가하려는 위치의 노드
Node<E> next_Node = prev_Node.next;
// 추가하려는 노드
Node<E> newNode = new Node<E>(value);
// 이전 노드가 가리키는 노드를 끊은 뒤 새 노드로 변경해준다.
// 또한 새 노드가 가리키는 노드는 next_Node로 설정해준다.
prev_Node.next = null;
prev_Node.next = newNode;
newNode.next = next_Node;
size++;
}
remove 메소드 구현
가장 앞의 요소(head)를 삭제 - remove()
특정 index의 요소를 삭제 - remove(int index)
특정 요소를 삭제 - remove(Object value)
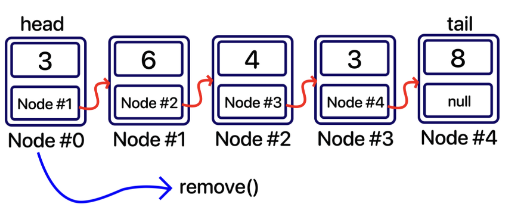
remove() : 처음 노드 삭제
remove() 는 ‘가장 앞에 있는 요소’를 제거하는 것이다.
→ head 가 가리키는 요소만 없애주면 된다는 뜻
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
public E remove() {
Node<E> headNode = head;
if (headNode == null)
throw new NoSuchElementException();
// 삭제된 노드를 반환하기 위한 임시 변수
E element = headNode.data;
// head의 다음 노드
Node<E> nextNode = head.next;
// head 노드의 데이터들을 모두 삭제
head.data = null;
head.next = null;
// head 가 다음 노드를 가리키도록 업데이트
head = nextNode;
size--;
// 삭제된 요소가 리스트의 유일한 요소였을 경우 그 요소는 head 이자 tail이었으므로
// 삭제되면서 tail도 가리킬 요소가 없기 때문에 size가 0일경우 tail도 null로 변환
if(size == 0) {
tail = null;
}
return element;
}
리스트에 아무런 요소가 없는데 삭제를 시도하려는 경우 요소를 찾을 수 없기 때문에 NoSuchElementException() 예외를 던져주었다.
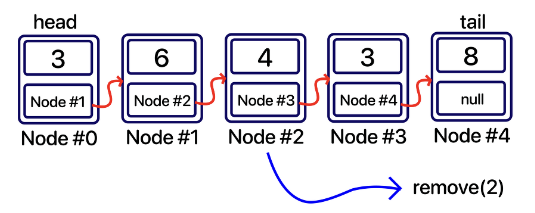
remove(int index)
remove(int index) 메소드는 사용자가 원하는 특정 위치(index)를 리스트에서 찾아서 삭제한다.
*add(int index, E value) 와 정반대로 구현해주면 된다.
삭제하려는 노드의 이전 노드의 next 변수를 삭제하려는 노드의 다음 노드를 가리키도록 해주면 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
@Override
public E remove(int index) {
// 삭제하려는 노드가 첫 번째 원소일 경우
if (index == 0) {
return remove();
}
// 잘못된 범위에 대한 예외
if (index >= size || index < 0) {
throw new IndexOutOfBoundsException();
}
Node<E> prevNode = search(index - 1); // 삭제할 노드의 이전 노드
Node<E> removedNode = prevNode.next; // 삭제할 노드
Node<E> nextNode = removedNode.next; // 삭제할 노드의 다음 노드
E element = removedNode.data; // 삭제되는 노드의 데이터를 반환하기 위한 임시변수
// 이전 노드가 가리키는 노드를 삭제하려는 노드의 다음노드로 변경
prevNode.next = nextNode;
// 만약 삭제했던 노드가 마지막 노드라면 tail을 prevNode로 갱신
if(prevNode.next == null) {
tail = prevNode;
}
// 데이터 삭제
removedNode.next = null;
removedNode.data = null;
size--;
return element;
}
*노드를 얻기 위해 기존에 작성했던 search() 메소드를 이용하면 쉽게 얻을 수 있다.
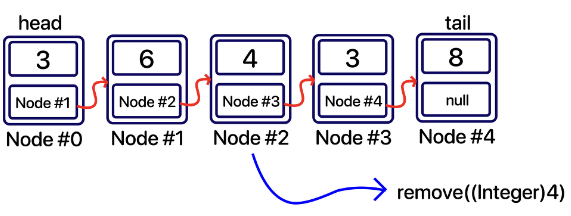
remove(Object value)
remove(Object value) 메소드는 사용자가 원하는 특정 요소(value)를 리스트에서 찾아서 삭제한다.
remove(int index) 메소드하고 동일한 메커니즘으로 작동한다.
다만 고려해야 할 점은 ‘삭제하려는 요소가 존재하는지’를 염두해두어야 한다.
예로들어 삭제하려는 요소를 찾지 못했을 경우 false를 반환해주고, 만약 찾았을 경우 remove(int index) 와 동일한 삭제 방식을 사용하면 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
@Override
public boolean remove(Object value) {
Node<E> prevNode = head;
boolean hasValue = false;
Node<E> x = head; // removedNode
// value 와 일치하는 노드를 찾는다.
for (; x != null; x = x.next) {
if (value.equals(x.data)) {
hasValue = true;
break;
}
prevNode = x;
}
// 일치하는 요소가 없을 경우 false 반환
if(x == null) {
return false;
}
// 만약 삭제하려는 노드가 head라면 기존 remove()를 사용
if (x.equals(head)) {
remove();
return true;
}
else {
// 이전 노드의 링크를 삭제하려는 노드의 다음 노드로 연결
prevNode.next = x.next;
// 만약 삭제했던 노드가 마지막 노드라면 tail을 prevNode로 갱신
if(prevNode.next == null) {
tail = prevNode;
}
x.data = null;
x.next = null;
size--;
return true;
}
}
부가기능
get(int index)
index 로 들어오는 값을 인덱스삼아 해당 위치에 있는 요소를 반환하는 메소드다.
이전에 search() 메소드를 구현해놓았기 때문에 이를 이용했다.
1
2
3
4
@Override
public E get(int index) {
return search(index).data;
}
🐣 search() 내부에서 잘못된 위치일 경우 예외를 던지기 때문에 따로 예외처리를 해줄 필요는 없다.
set(int index, E value)
set 메소드는 기존에 index에 위치한 데이터를 새로운 데이터(value)으로 ‘교체’하는 것이다.
결과적으로 index에 위치한 데이터를 교체하는 것이기 때문에 마찬가지로 search() 메소드를 사용하여 노드를 찾아내고,
해당 노드의 데이터만 새로운 데이터로 변경해주면 된다.
1
2
3
4
5
6
7
@Override
public void set(int index, E value) {
Node<E> replaceNode = search(index);
replaceNode.data = null;
replaceNode.data = value;
}
indexOf(Object value)
indexOf 메소드는 사용자가 찾고자 하는 요소(value)의 ‘위치(index)’를 반환하는 메소드다.
찾고자 하는 요소가 중복된다면 가장 먼저 마주치는 요소의 인덱스를 반환한다.
찾고자 하는 요소가 없다면요?” 이러한 경우 -1 을 반환한다.
⭐ 객체끼리 비교할 때는 동등연산자(==)가 아니라 반드시 .equals() 로 비교해야 한다.
객체끼리 비교할 때 동등연산자를 쓰면 값을 비교하는 것이 아닌 주소를 비교하는 것이기 때문에 잘못된 결과를 초래한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
@Override
public int indexOf(Object value) {
int index = 0;
for (Node<E> x = head; x != null; x = x.next) {
if (value.equals(x.data)) {
return index;
}
index++;
}
// 찾고자 하는 요소를 찾지 못했을 경우 -1 반환
return -1;
}
contains(Object value)
사용자가 찾고자 하는 요소(value)가 존재 하는지 안하는지를 반환하는 메소드다.
찾고자 하는 요소가 존재한다면 true를, 존재하지 않는다면 false를 반환한다.
해당 요소가 존재하는지를 ‘검사’한다는 기능은 같기 때문에 indexOf 메소드를 이용하여
만약 음수가 아닌 수가 반환되었다면 요소가 존재한다는 뜻이고, 음수(-1)이 나왔다면 요소가 존재하지 않는다는 뜻이다.
1
2
3
4
@Override
public boolean contains(Object item) {
return indexOf(item) >= 0;
}
size()
모든 리스트 자료구조는 기본적으로 동적 할당을 전제로 한다.
그만큼 요소들을 삽입, 삭제가 많아지면 사용자가 리스트에 담긴 요소의 개수가 몇 개인지 기억하기 힘들다.
그렇기에 size 변수의 값을 반환해주는 메소드인 size()를 만들어 줄 필요가 있다.
1
2
3
4
@Override
public int size() {
return size;
}
isEmpty()
현재 ArrayList에 요소가 단 하나도 존재하지 않고 비어있는지를 알려준다.
리스트가 비어있을 경우 true를, 비어있지 않고 단 한개라도 요소가 존재 할 경우 false를 반환해주면 된다.
→ size가 요소의 개수였으므로 size == 0 이면 true, 0 이 아니면 false 라는 것
1
2
3
4
@Override
public boolean isEmpty() {
return size == 0;
}
clear()
모든 요소들을 비워버리는 작업
리스트에 요소를 담아두었다가 초기화가 필요할 때 쓸 수 있는 유용한 존재다.
또한 모든 요소를 비워버린다는 것은 요소가 0개라는 말로 size 또한 0으로 초기화해준다.
이 때 그냥 객체 자체를 null 해주기 보다는 모든 노드를 하나하나 null 해주는 것이 자바의 가비지 컬렉터가 명시적으로 해당 메모리를 안쓴다고 인지하기 때문에 메모리 관리 효율 측면에서 조금이나마 더 좋다.
1
2
3
4
5
6
7
8
9
10
11
@Override
public void clear() {
for (Node<E> x = head; x != null;) {
Node<E> nextNode = x.next;
x.data = null;
x.next = null;
x = nextNode;
}
head = tail = null;
size = 0;
}
구현한 단일 연결리스트의 경우 삽입, 삭제 과정에서 ‘링크’만 끊어주면 되기 때문에 매우 효율적이라는 것을 볼 수가 있다.
반대로 모든 자료를 인덱스가 아닌 head부터 연결되어 관리하기 때문에 색인(access)능력은 떨어진다.