Jmh
JMH를 통한 벤치마킹 테스트
관련 글
- Websocket
- Websocket + 부가기능
- Websocket (채팅 기록 json 파일 저장하기)
- Sse
- Websocket + jwt
- Websocket test
- Jmh - 채팅 파일 refactoring 👈🏻
성능 테스트(JMH)
JMH는 Java Microbenchmark Harness의 약자로, Java 코드의 성능을 측정하고 비교하기 위한 도구다.
JMH를 사용하면 매우 정확하고 안정적인 벤치마크를 작성할 수 있다.
이를 통해 코드 변경에 따른 성능 변화를 측정하거나, 다양한 구현 방법의 성능을 비교 분석할 수 있다.
JMH는 측정 대상이 되는 코드가 얼마나 빠르게 동작하는지 측정하기 위해 성능 측정 도구를 사용한다.
JMH는 매우 정교하고 통계학적으로 유효한 측정 결과를 얻기 위해 다양한 성능 측정 방법과 통계 기법을 적용한다.
JMH는 Oracle의 JIT Compiler 개발자가 만든 것이기 때문에 타 Benchmark Framework 보다 신뢰할 수 있다는 장점이 존재한다.
설정
위와 같이 src directory 하위에 jmh 폴더를 만들고 main과 같은 형태로 폴더를 구성했다.
1
2
3
4
5
프로젝트 폴더
└─── src
└─── jmh
├─── java
└─── resources
1
2
3
4
5
6
7
8
plugins {
id "me.champeau.jmh" version "0.6.4"
}
jmh{
fork = 1
warmupIterations = 10
iterations = 10
}
jmh는 성능 측정을 위한 도구이며, 위 설정은 jmh 프로파일러가 성능 측정을 어떻게 수행할지 제어하는 데 사용된다.
fork: 측정할 코드를 포크할 횟수를 지정한다.
몇 번의 자식 프로세스를 만들어서 벤치마크를 실행할 것인지를 결정한다.(default 1)
이 값이 1이면 측정할 코드를 한 번만 포크하며, 이 값이 높을수록 측정 결과의 신뢰성이 높아진다.
하지만 여러 개의 JVM에서 동일한 벤치마크를 실행하고 결과를 평균화하는 것이 더 정확할 수도 있다.
warmupIterations: 실제 측정을 시작하기 전에 성능 측정을 위한 샘플 데이터를 생성하는 데 사용되는 반복 횟수를 지정한다. (default 10)
벤치마크를 실행하기 전에 JVM이 최적화를 수행할 수 있도록 JVM을 미리 ‘워밍업’하는 데 필요한 반복 횟수를 결정한다.
이 값은 높으면 더 많은 최적화가 이루어지므로 정확도가 높아진다.
하지만 반복이 길어지므로 실행 시간이 늘어난다.
iterations: 실제 측정을 수행하는 반복 횟수를 지정한다. (default 10)
이 값이 높을수록 측정 결과의 신뢰성이 높아진다.
하지만 높은 값은 실행 시간이 길어지므로 효율성을 떨어뜨릴 수 있다.
보통은 fork는 1이나 2로 설정하고, warmupIterations와 iterations는 기본값으로 두는 것이 좋다.
그리고 실제로 최적화된 결과를 얻기 위해서는 여러 차례의 실행을 거쳐 평균값을 구해야 한다.
*참고 : JMH의 최신 버전 직접 반영해주는 방법
1
2
3
4
5
dependencies {
// JMH
implementation 'org.openjdk.jmh:jmh-core:1.32'
implementation 'org.openjdk.jmh:jmh-generator-annprocess:1.32'
}
Warmup
JVM warm-up은 코드 실행 전에 JVM을 최적화하고 성능을 향상시키는 과정을 말한다.
이 과정은 JIT(Just-In-Time) 컴파일러와 관련이 있는데,
컴파일러는 프로그램 실행 중에 실제로 사용되는 코드 블록을 감지하고 네이티브 코드로 컴파일하여 성능을 향상시킨다.
네이티브 코드는 컴퓨터의 특정 플랫폼에서 직접 실행할 수 있는 기계어 코드를 말한다.
자바 코드는 JVM(Java Virtual Machine)에서 실행되므로 플랫폼에 구애받지 않고 실행될 수 있다.
JIT(Just-In-Time) 컴파일러는 프로그램 실행 중에
필요한 코드 블록을 선택하여 해당 부분을 네이티브 코드로 변환하여 실행 속도를 높인다.
네이티브 코드로 변환된 코드는 해당 플랫폼에서 직접 실행되므로 보통 실행 속도가 빠르다.
간단한 예로, 자바 프로그램에서 작성한 코드는 먼저 자바 바이트 코드로 변환된다.
JVM은 필요에 따라 JIT(Just-In-Time) 컴파일러를 사용하여 바이트 코드를 해당 플랫폼의 네이티브 코드로 변환한다.
네이티브 코드로 변환되면 해당 플랫폼에서 직접 실행될 수 있으며 실행 속도가 빨라진다.
기계어 코드는 CPU가 직접 이해하고 실행하는 이진 형식의 코드다.
이 코드는 0과 1로 표현되며, CPU가 직접 해석하여 실행한다.
따라서 기계어 코드는 특정 CPU 아키텍처에 의해 이해되고 실행된다.
그러나 JIT 컴파일러는 프로그램의 초기 실행에서는 모든 코드를 네이티브 코드로 컴파일하지 않고,
필요한 부분만 선택적으로 컴파일한다.
이로 인해 초기 실행의 성능이 최적화되지 않은 상태로 유지될 수 있다.
Warmup을 사용하면 자주 사용되는 클래스를 호출하여 클래스를 메모리에 로딩하고 코드 캐시를 생성한다.
이를 통해 코드의 실행 속도를 향상시키고 성능 차이를 최소화할 수 있다.
주로 운영환경에서 서버를 재가동하거나,
성능 측정 테스트를 수행하기 전에 warm-up을 실행하여 JVM을 최적화하고 안정화된 상태로 성능 측정을 진행한다.
이를 통해 초기 실행의 성능 저하를 최소화하고 일관된 성능 측정 결과를 얻을 수 있다.
1
2
3
4
5
6
7
8
plugins {
id "me.champeau.jmh" version "0.6.4"
}
jmh{
fork = 1
warmupIterations = 10
iterations = 10
}
이 전에 warmupIterations를 10으로 설정했는데 특정 class에서 5로 설정하고 싶다면
@Warmup(iterations = 5)와 같이 적으면 된다.
1
2
3
@Warmup(iterations = 5)
public class Benchmark {
}
JMH 작성 방법
@BenchmarkMode: 벤치마크 결과를 나타내는 모드를 설정한다.
- Mode.Throughput : 시간당 처리량 측정
- Mode.AverageTime : 평균 실행 시간 측정
- Mode.SampleTime : 실행 시간 샘플링 측정
- Mode.SingleShotTime : 단일 실행 시간 측정
- Mode.All : 모든 시간 측정
ex. @BenchmarkMode(Mode.AverageTime)으로 설정하면 평균 실행 시간이 결과로 나타난다.
@OutputTimeUnit: 결과의 시간 단위를 설정한다.
- TimeUnit.NANOSECONDS : 나노
- TimeUnit.MICROSECONDS : 마이크로
- TimeUnit.MILLISECONDS : 밀리
- TimeUnit.SECONDS : 초
- TimeUnit.MINUTES : 분
- TimeUnit.HOURS : 시간
- TimeUnit.DAYS : 일
ex) @OutputTimeUnit(TimeUnit.MILLISECONDS)와 같이 설정하면 결과를 밀리초 단위로 출력한다.
@State : 벤치마크할 상태를 설정한다.
- Scope.Benchmark : 벤치마크 전체에서 공유
- Scope.Thread : 각 스레드마다 별도로 생성. 멀티스레드 환경에서 안전
- Scope.Group : 벤치마크 실행 그룹에서 공유
@State(Scope.Benchmark): 벤치마크 메서드마다 객체를 새로 생성하지 않고 상태를 유지하며 벤치마크를 수행한다.
@Setup: 벤치마크 메서드 실행 전에 초기화 작업을 수행한다.
주로 파일 경로 설정 등의 환경 설정 작업을 수행한다.
- Level.Trial : 벤치마크 전체에서 한 번만 실행 (default)
- Level.Iteration : 벤치마크 반복마다 실행
- Level.Invocation : 각 메서드 호출마다 실행
@TearDown : 벤치마크 메서드 실행 후에 정리 작업을 수행한다.
- Scope.Benchmark : 벤치마크 전체에서 공유
- Scope.Thread : 각 스레드마다 별도로 생성. 멀티스레드 환경에서 안전
- Scope.Group : 벤치마크 실행 그룹에서 공유
1. 클래스에 @State(Scope.Benchmark) 어노테이션을 붙여 벤치마크할 상태를 지정한다.
2. 클래스에 @BenchmarkMode(Mode.AverageTime) 어노테이션을 붙여 벤치마크 결과를 나타내는 모드를 설정한다.
3. 클래스에 @OutputTimeUnit(TimeUnit.MILLISECONDS) 어노테이션을 붙여 결과의 시간 단위를 설정한다.
4. 각 벤치마크 대상 메소드에 @Benchmark 어노테이션을 붙인다.
5. 필요한 경우 @Setup 어노테이션을 이용해 벤치마크 실행 전에 필요한 초기화 작업을 수행한다.
이렇게 기존 로직을 가지고 똑같이 작성하되 jmh에 필요한 어노테이션을 붙여 벤치마크를 작성하면 된다.
JMH 실행 방법
terminal에서 gradlew가 있는 최상위 디렉토리로 이동한 후 아래 명령어 입력
1
./gradlew jmh
위와 같이 입력하면 terminal에 실행 결과가 뜨지만 아래와 같이 입력해도 된다.
1
cat build/results/jmh/results.txt
JMH 기록을 모두 지우려면 아래와 같이 작성한다.
1
2
./gradlew clean
파일 마지막 글만 조회하기
1차 수정
*전체코드는 길어서 생략 → github 참고하거나 파일 조회 코드(제일 하단)에 설명 작성한 것 보기
1
2
3
4
5
jmh{
fork = 1
warmupIterations = 1
iterations = 1
}

변경 전 코드는 파일의 끝에서부터 7줄을 읽어올 때 파일 포인터를 이용하여 하나씩 읽어오는 방식을 사용한다.
(가독성이 좋게 변수별로 한 줄 씩 파일에 저장해서 총 7줄을 읽어야 했다.)
사실 이 부분 때문에 jmh를 사용한 이유기도 하다.
해당 방식 때문에 채팅 리스트를 여는 시간이 느리다고 판단되었고 파일을 저장하는 방식을 변경했다.
파일을 저장할 때 한 줄 안에 모든 정보를 저장하게 한 다음 파일을 읽어올 때
파일 포인터를 끝에서 두 번째 줄로 시작 지점을 이동시킨 다음에 한 줄을 읽고 끝낸다.
(한 줄을 저장하고 줄을 한칸 띄어 저장하기 때문에)
이 방식은 파일 포인터 이동 횟수가 적기 때문에 더 빠른 성능을 보이는 것 같다.
1
2
3
4
5
jmh{
fork = 1
warmupIterations = 10
iterations = 1
}
위와 같이 설정 후 다시 실행했을 때 차이가 더 커진 것을 볼 수 있다.

샘플 데이터와 실제 데이터를 10으로 설정하고 실행했다.
1
2
3
4
5
jmh{
fork = 1
warmupIterations = 10
iterations = 10
}
- Cnt : 총 시행 횟수(포크*반복)
- 점수 : 벤치마크 결과
- 오류 : 표준 오류 값. 서로 다른 시행 결과가 얼마나 다른지를 의미
“testImproved”의 실행 시간은 평균 1.860 ms/op로 나타났으며, 에러 범위는 ±0.465 ms/op다.
“testOriginal”의 실행 시간은 평균 154.466 ms/op로 나타났으며, 에러 범위는 ±51.680 ms/op다.
testImproved와 testOriginal 간의 실행 시간 차이가 대략 150배이며, 에러 범위도 50배 정도 줄었다.
마지막 글만 가져오는 코드는 확실히 성능이 개선되어 보인다.
그외 다른 log들
1
2
3
4
Result "LastLineBenchmark.testImproved":
1.860 ±(99.9%) 0.465 ms/op [Average]
(min, avg, max) = (1.566, 1.860, 2.398), stdev = 0.308
CI (99.9%): [1.395, 2.325] (assumes normal distribution)
(min, avg, max) = (1.566, 1.860, 2.398), stdev = 0.308
testImproved의 실행 시간에 대한 최소값, 평균값, 최대값, 표준 편차를 나타낸다.
최소값은 1.566 ms/op, 평균값은 1.860 ms/op, 최대값은 2.398 ms/op, 표준 편차는 0.308 ms/op다.
CI (99.9%): [1.395, 2.325] (assumes normal distribution)
testImproved의 실행 시간에 대한 99.9% 신뢰 구간을 나타낸다.
여기서는 1.395 ms/op에서 2.325 ms/op 사이의 값들이 99.9%의 확률로 실제 평균값을 포함한다고 추정된다.
신뢰 구간은 실행 시간 추정의 정확성과 신뢰도를 나타낸다.
1
2
3
4
Result "LastLineBenchmark.testOriginal":
154.466 ±(99.9%) 51.680 ms/op [Average]
(min, avg, max) = (97.067, 154.466, 222.105), stdev = 34.183
CI (99.9%): [102.786, 206.146] (assumes normal distribution)
2차 수정
Map을 추가하여 file 조회 전 map의 값 유무에 따라 map에서 조회하거나 file에서 조회 하는 방식
1
2
3
4
5
6
7
8
9
10
public LastMessage lastLine(String roomId) {
if(lastMessageMap.containsKey(roomId)){
log.info(" = = = MAP 활용 = = = ");
return lastMessageMap.get(roomId);
}else{
log.info(" = = = MAP 활용 X = = = ");
String filePath = chatUploadLocation + "/" + roomId + ".txt";
// 이하 변경 전 코드와 동일
}
}
과연 파일 조회만 했을 때보다 map을 활용해서 file 조회를 덜 하는 방식이 얼마나 효과적일지 체크해봤다.
또, 처음에 작성한 코드와 얼마나 차이가 나는지 확인하기 위해
작성한 순서대로 결과를 띄우려고 메소드 명 앞에 A, B, C, … 를 넣었다.
Map 조회만 했을 때 ms로는 시간측정이 되지 않아서 ns로 측정했다.
1
2
3
4
5
jmh{
fork = 1
warmupIterations = 10
iterations = 10
}
1
2
3
4
5
@State(Scope.Benchmark)
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
public class LastLineBenchmark {
}
map의 값 유무에 따라 map에서 조회하거나 file에서 조회 하는 방식을 jmh에서 사용하기 위해
file에서 먼저 조회하고 file 조회 로직에 map에 값을 넣는 로직을 추가했다.
내가 최종적으로 작성한 코드를 반영한 메서드는 getFileAftergetMap이다.
jmh 결과를 통해 AtestOriginal 메서드는 파일을 열어서 7줄을 읽는 코드로,
BtestImproved는 1줄만 읽는 코드로 개선되었다.
그리고 DgetFileAftergetMap는 1줄을 읽지만 파일로만 읽지 않고 map의 값을 활용하는 코드다.
FonlyGetMap과 ConlyGetFile의 코드를 합친 것이 DgetFileAftergetMap인데,
하나만 실행했을 때 시간차이를 체크하기 위해 작성했다.
참고로 BtestImproved와 ConlyGetFile의 시간차이가 나는 이유는
코드를 수정하면서 일부 변수들을 더 추가하고 저장하면서 코드의 수정이 일어났기 때문에
약간의 차이가 나는 것이다.
평균적으로 파일로만 조회하는 경우 약 2.42초가 걸리는 반면,
파일을 조회한 후에 map을 조회할 때의 실행 시간이 더 빠르다는 것을 알 수 있다.
이를 통해 파일 조회를 최소화하고, map과 같은 메모리 캐싱을 활용하는 것이 효율적인 것으로 판단된다.
파일 조회 코드 성능 비교
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
@State(Scope.Benchmark)
public class ReadFileBenchmark {
private String chatUploadLocation;
@Setup
public void setup() {
chatUploadLocation = "./src/main/resources/static/files/";
}
@Benchmark // 벤치마크 대상 메소드
public Object readFileBefore() throws IOException, ParseException {
String roomId = "111";
String str = Files.readString(Paths.get(chatUploadLocation + "/" + roomId + ".txt"));
JSONParser parser = new JSONParser();
return parser.parse("[" + str + "]");
}
@Benchmark // 벤치마크 대상 메소드
public Object readFileAfter() throws IOException, ParseException {
String roomId = "111";
List<String> lines = Files.lines(Paths.get(chatUploadLocation, roomId + ".txt")).collect(Collectors.toList());
String jsonString = "[" + String.join(",", lines) + "]";
JSONParser parser = new JSONParser();
return parser.parse(jsonString);
}
}
JMH(Java Microbenchmark Harness)을 사용하여 두 개의 파일 읽기 메소드를 벤치마크하는 코드다.
JMH는 자바 마이크로 벤치마크 프레임워크로, 자바 성능 측정을 위해 만들어졌다.
이 코드는 두 개의 메소드를 실행하여 파일을 읽은 후, 결과를 비교한다.
readFileBefore() 메소드는 Files.readString() 메소드를 사용하여 파일을 읽는다.
readFileAfter() 메소드는 Files.lines() 메소드를 사용하여 파일을 한 줄씩 읽은 후, 리스트에 담아서 문자열로 변환한다.
두 개의 메소드를 실행하여 각각의 실행 시간을 측정한 후, 결과를 비교하여 성능을 개선하였는지 확인할 수 있다.
실행
마지막 글만 가져오기 성능비교와는 다르게 큰 차이는 없어보인다.
1
2
3
4
5
jmh{
fork = 1
warmupIterations = 10
iterations = 1
}
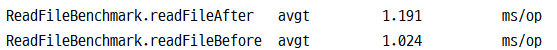
1
2
3
4
5
jmh{
fork = 1
warmupIterations = 10
iterations = 10
}
log
1
2
3
4
5
6
7
8
9
10
Result "ReadFileBenchmark.readFileAfter":
1.155 ±(99.9%) 0.232 ms/op [Average]
(min, avg, max) = (0.929, 1.155, 1.411), stdev = 0.154
CI (99.9%): [0.923, 1.388] (assumes normal distribution)
Result "ReadFileBenchmark.readFileBefore":
1.212 ±(99.9%) 0.652 ms/op [Average]
(min, avg, max) = (0.854, 1.212, 2.339), stdev = 0.431
CI (99.9%): [0.560, 1.864] (assumes normal distribution)
*파일 저장하기는 변경된 부분이 거의 없으므로 성능의 큰 차이가 없을 것이다.
따라서 JMH 코드를 작성할 필요가 없다.
코드의 가독성을 높이거나 코드 스타일을 변경하는 경우에는 JMH 코드를 작성할 필요가 없다.
코드를 변경했을 때 성능이 향상되지 않았더라도 가독성이 높아진다면, 코드를 이해하기 쉬워지므로 변경한 것이 좋다.
메소드를 벤치마크한다는 것은 해당 메소드를 실행하여 소요되는 시간, CPU 사용량 등의 성능 지표를 측정하고 분석하는 것을 말한다.
즉, 해당 메소드의 성능을 정량적으로 측정하여,
application의 병목 구간이나 성능 개선이 필요한 부분을 파악하고 개선할 수 있는 기반을 마련하는 것이다.
벤치마크를 통해 개선된 성능은 사용자 경험을 향상시키고, 서버의 처리량을 증가시키며, 더 나은 확장성과 안정성을 제공할 수 있다.
변경 전 후 코드
파일 저장하기
변경 전
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
public void saveFile(ChatMessage chatMessage) { // 파일 저장
if (connectUsers.get(chatMessage.getRoomId()) != 0) {
if ((chatMessage.getType().toString()).equals("JOIN")) {
reset(chatMessage.getSender(), chatMessage.getRoomId());
} else {
countChat(chatMessage.getSender(), chatMessage.getRoomId());
}
}
JsonObject jsonObject = new JsonObject();
jsonObject.addProperty("roomId", chatMessage.getRoomId());
if (chatMessage.getType().toString().equals("JOIN")) {
jsonObject.addProperty("type", "JOINED");
} else {
jsonObject.addProperty("type", chatMessage.getType().toString());
}
jsonObject.addProperty("sender", chatMessage.getSender());
jsonObject.addProperty("message", chatMessage.getMessage());
jsonObject.addProperty("adminChat", adminChat.get(chatMessage.getRoomId()));
jsonObject.addProperty("userChat", userChat.get(chatMessage.getRoomId()));
Gson gson = new GsonBuilder().setPrettyPrinting().create();
String json1 = gson.toJson(jsonObject);
try {
FileWriter file = new FileWriter(chatUploadLocation + "/" + chatMessage.getRoomId() + ".txt", true);
File file1 = new File(chatUploadLocation + "/" + chatMessage.getRoomId() + ".txt");
if (file1.exists() && file1.length() == 0) {
file.write(json1);
chatAlarm(chatMessage.getSender(), chatMessage.getRoomId());
} else {
file.write("," + json1);
}
file.flush();
file.close(); // 연결 끊기
} catch (IOException e) {
log.error("[error] " + e);
}
}
변경 후
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
public void saveFile(ChatMessage chatMessage) {
if (connectUsers.get(chatMessage.getRoomId()) != 0) {
if (chatMessage.getType() == ChatMessage.MessageType.JOIN) {
reset(chatMessage.getSender(), chatMessage.getRoomId());
} else {
countChat(chatMessage.getSender(), chatMessage.getRoomId());
}
}
JsonObject jsonObject = new JsonObject();
jsonObject.addProperty("roomId", chatMessage.getRoomId());
if (chatMessage.getType() == ChatMessage.MessageType.JOIN){
jsonObject.addProperty("type", "JOINED");
}else {
jsonObject.addProperty("type", chatMessage.getType().toString());
}
jsonObject.addProperty("sender", chatMessage.getSender());
jsonObject.addProperty("message", chatMessage.getMessage());
jsonObject.addProperty("adminChat", adminChat.get(chatMessage.getRoomId()));
jsonObject.addProperty("userChat", userChat.get(chatMessage.getRoomId()));
Gson gson = new Gson();
String json = gson.toJson(jsonObject);
try (PrintWriter out = new PrintWriter(new BufferedWriter(new FileWriter(chatUploadLocation + "/" + chatMessage.getRoomId() + ".txt", true)))){
if (new File(chatUploadLocation + "/" + chatMessage.getRoomId() + ".txt").length() == 0) {
out.println(json);
chatAlarm(chatMessage.getSender(), chatMessage.getRoomId());
} else {
out.println("," + json);
}
} catch (IOException e) {
log.error("[error] " + e);
}
}
파일을 저장할 때 사용하는 FileWriter 클래스를 PrintWriter 클래스로 대체했다.
코드 중간에 조건문을 수정하여 ChatMessage 클래스의 type 속성을 확인할 때 toString() 메서드를 사용하지 않고,
ChatMessage.MessageType.JOIN과 같이 enum 상수를 사용하여 비교하는 것으로 변경했다.
Gson 클래스를 생성할 때 setPrettyPrinting() 메서드를 사용하지 않아서 코드가 더 간결해졌다.
setPrettyPrinting() 메서드는 JSON 데이터를 출력할 때 들여쓰기를 적용하는 기능인데, 이 기능이 필요하지 않아서 생략했다.
PrintWriter와 FileWriter 차이 → “data를 출력시키는 방법”
개행을 하게 될 때 PrintWriter에서는 println()을 사용하여 자동으로 해주지만
FileWriter는 직접 덧붙여야 한다.
참고 글 : PrintWriter과 FileWriter 차이
파일 조회하기
변경 전
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public Object readFile(String roomId) {
long startTime = System.currentTimeMillis();
try {
String str = Files.readString(Paths.get(chatUploadLocation + "/" + roomId + ".txt"));
JSONParser parser = new JSONParser();
Object obj = parser.parse("[" + str + "]");
long stopTime = System.currentTimeMillis();
log.info("readFile : " + (stopTime - startTime) + " 초");
return obj;
} catch (NoSuchFileException e) {
throw new FileNotFoundException();
} catch (IOException | ParseException e) {
log.error("[error] " + e);
return null;
}
}
변경 후
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public Object readFile(String roomId) {
long startTime = System.currentTimeMillis();
try {
List<String> lines = Files.lines(Paths.get(chatUploadLocation, roomId + ".txt")).collect(Collectors.toList());
String jsonString = "[" + String.join(",", lines) + "]";
JSONParser parser = new JSONParser();
Object obj = parser.parse(jsonString);
long stopTime = System.currentTimeMillis();
log.info("readFile : " + (stopTime - startTime) + " 초");
return obj;
} catch (NoSuchFileException e) {
throw new FileNotFoundException();
} catch (IOException | ParseException e) {
log.error("[error] " + e);
return null;
}
}
Files.readString()을 사용하여 파일의 내용을 가져왔지만,
변경 코드에서는 Files.lines()를 사용하여 각 라인을 읽어들인 후 String.join()을 사용하여 하나의 JSON 문자열로 결합했다.
또한 Collectors.toList()를 사용하여 리스트로 변환한 후 String.join()을 사용하여 결합했다.
파일 마지막 json만 조회
변경 전
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
public List lastLine(String roomId) {
try{
// 2. 뒤에서 7줄 읽기
RandomAccessFile file = new RandomAccessFile(chatUploadLocation + "/" + roomId + ".txt", "r");
StringBuilder lastLine = new StringBuilder();
int lineCount = 7;
// 2. 전체 파일 길이
long fileLength = file.length();
// 3. 포인터를 이용하여 뒤에서부터 앞으로 데이터를 읽는다.
for (long pointer = fileLength - 1; pointer >= 0; pointer--) {
// 3.1. pointer를 읽을 글자 앞으로 옮긴다.
file.seek(pointer);
// 3.2. pointer 위치의 글자를 읽는다.
char c = (char) file.read();
// 3.3. 줄바꿈이 7번(lineCount) 나타나면 더 이상 글자를 읽지 않는다.
if (c == '\n') {
lineCount--;
if (lineCount == 0) {
break;
}
}
// 3.4. 결과 문자열의 앞에 읽어온 글자(c)를 붙여준다.
lastLine.insert(0, c);
}
StringTokenizer st = new StringTokenizer(lastLine.toString(), ",");
String roomNum = st.nextToken().trim();
String type = st.nextToken().trim();
String sender = st.nextToken().trim();
String msg = st.nextToken().trim();
String admin = st.nextToken().trim();
String user = StringUtils.removeEnd(st.nextToken().trim(), "}");
String adminChat = admin.substring(admin.indexOf("adminChat")+12);
String userChat = user.substring(user.indexOf("userChat")+11);
String message = msg.substring(msg.indexOf("message")+10);
String messages = new String(message.getBytes("iso-8859-1"), "utf-8");
List<String> chat = new ArrayList<>();
chat.add(adminChat.trim());
chat.add(userChat.trim());
chat.add(messages.trim());
return chat;
// 4. 결과 출력
}catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return new ArrayList<>();
}
변경 후
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
public List<String> lastLine(String roomId) {
try (RandomAccessFile file = new RandomAccessFile(chatUploadLocation + "/" + roomId + ".txt", "r")) {
long fileLength = file.length();
// 파일 포인터를 파일 끝으로 이동시킴
file.seek(fileLength);
// 파일 포인터를 끝에서 두 번째 줄의 시작 지점으로 이동시킴
long pointer = fileLength - 2;
while (pointer > 0) {
file.seek(pointer);
char c = (char) file.read();
if (c == '\n') {
break;
}
pointer--;
}
file.seek(pointer + 1);
// 두 번째 줄의 내용을 읽어서 반환함
String line = file.readLine();
if (line == null || line.trim().isEmpty()) {
return Collections.emptyList();
}
if (line.startsWith(",")) {
line = line.substring(1);
}
JSONObject json = new JSONObject(line);
int adminChat = json.getInt("adminChat");
int userChat = json.getInt("userChat");
String message = json.getString("message").trim();
String messages = new String(message.getBytes("iso-8859-1"), "utf-8");
List<String> chat = new ArrayList<>();
chat.add(Integer.toString(adminChat));
chat.add(Integer.toString(userChat));
chat.add(messages);
return chat;
} catch (IOException | JSONException e) {
e.printStackTrace();
return Collections.emptyList();
}
}
파일이 저장될 때 마지막 줄은 공백으로 비워져 있다.
그래서 끝에서 2번째 줄을 가지고 오는 코드로 작성했다.
try-with-resources 구문을 사용하여 파일
close()를 명시적으로 호출하지 않아도 자동으로 파일을 닫아준다.파일 포인터를 끝에서 두 번째 줄의 시작 지점으로 이동시켜서 파일을 한 번만 읽어도 되도록 개선되었다.
이전 코드에서는 파일의 끝부터 7줄을 읽어야 했다.
불필요한 문자열 처리가 제거되어 코드가 간결해졌다.
이전 코드에서는 문자열을 분리하고 다시 합치는 등의 작업이 있었지만,
변경된 코드에서는 JSON 객체를 바로 파싱하여 필요한 값을 추출했다.
변경된 코드는 이전 코드보다 효율적이고 간결해졌다.
2차 수정
채팅방을 키고 닫고를 자주 하면서 계속 파일을 열고 마지막 글을 가져오는 시간이 너무 많이 소요되는 것 같아 수정했다.
채팅을 할 때 HashMap으로 값을 변경하면서 가장 최근에 작성한 글만 담아두고 있다가
채팅방 리스트를 띄울 때 가장 최근의 글을 HashMap으로 값을 가져오게 했다.
위에서 작성했던 코드는 채팅을 입력하지 않은 처음 시작할 때만 실행되고 그 이후에는 HashMap을 활용하게 했다.
lastMessageMap은 채팅을 하면 해당 기록을 파일에 저장 하는 과정에서 update하게 된다.
그 과정에서 return값을 DTO로 변경하고 dto에서 활용할 때 list.get(0) 과 같이
순서에 의해 값을 설정했는데 dto에서 값을 꺼내오는 것으로 변경했다.
파일 저장 method 코드 추가
1
2
3
// 파일 저장 메소드 내 코드 추가
LastMessage lastMessage = LastMessage.of(chatMessage, adminCnt, userCnt, days, time);
lastMessageMap.put(chatMessage.getRoomId(), lastMessage);
Dto
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
// 변경 전
public static ChatRoomDto of(String roomId, String nickname, User user, List<String> list) {
return ChatRoomDto.builder()
.roomId(roomId)
.nickname(user.getNickname())
.adminChat(Integer.valueOf(list.get(0)))
.userChat(Integer.valueOf(list.get(1)))
.message(list.get(2))
.day(list.get(3))
.time(list.get(4))
.build();
}
// 변경 후
public static ChatRoomDto of(String roomId, User user, LastMessage lastMessage) {
return ChatRoomDto.builder()
.roomId(roomId)
.nickname(user.getNickname())
.adminChat(lastMessage.getAdminChat())
.userChat(lastMessage.getUserChat())
.message(lastMessage.getMessage())
.day(lastMessage.getDay())
.time(lastMessage.getTime())
.build();
}
최근 채팅 기록 가져오기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
private Map<String, LastMessage> lastMessageMap;
@PostConstruct // @PostConstruct는 의존성 주입이 이루어진 후 초기화를 수행하는 메서드
private void setUp() {
this.lastMessageMap = new ConcurrentHashMap<>();
}
public LastMessage lastLine(String roomId) {
if(lastMessageMap.containsKey(roomId)){
log.info(" = = = MAP 활용 = = = ");
return lastMessageMap.get(roomId);
}else{
log.info(" = = = MAP 활용 X = = = ");
String filePath = chatUploadLocation + "/" + roomId + ".txt";
// 이하 변경 전 코드와 동일
}
}
Reference