Db 저장하기
New Project
새로운 프로젝트를 시작했다.
영어 공부에 대한 필요성이 느껴져 코딩 연습과 함께 영어 공부 사이트를 만들어 보려고 했다.
전체코드는 eng에서 확인할 수 있다.
IDEA
아이디어는 별도의 노션에서 계속 정리하고 있으며, 중간에 추가 및 수정이 많아 현재까지 완료한 작업들을 정리하기로 했다.
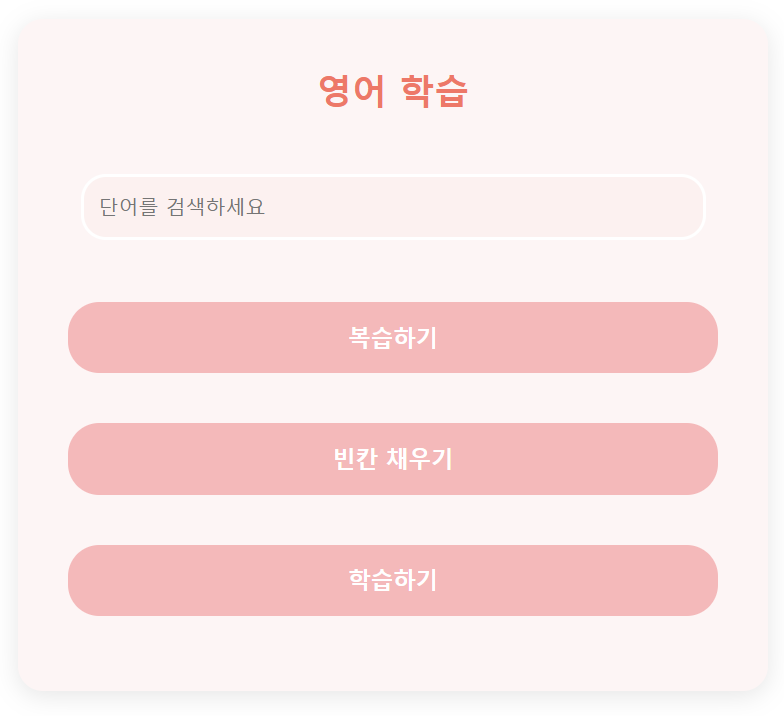
현재 기본적인 구조는 영어 단어 학습과, 빈칸 채우기 퀴즈, 그리고 틀린 부분을 모아서 복습하는 사이트다.
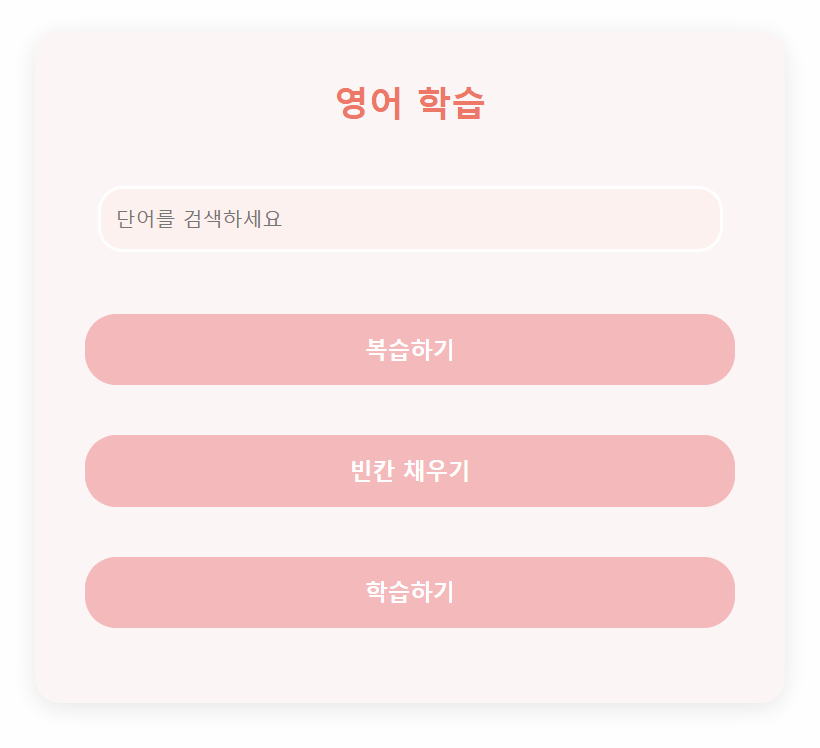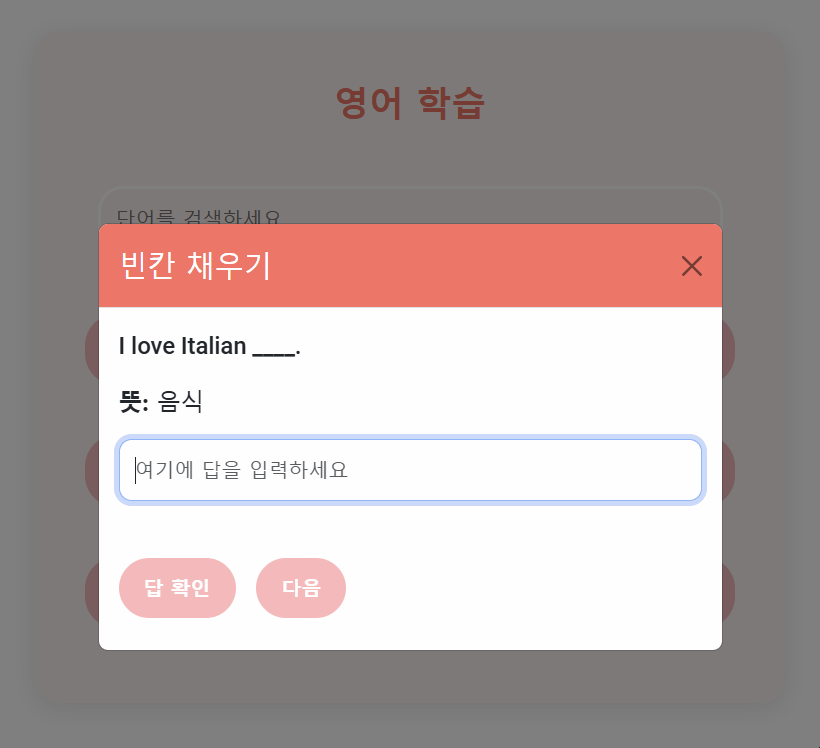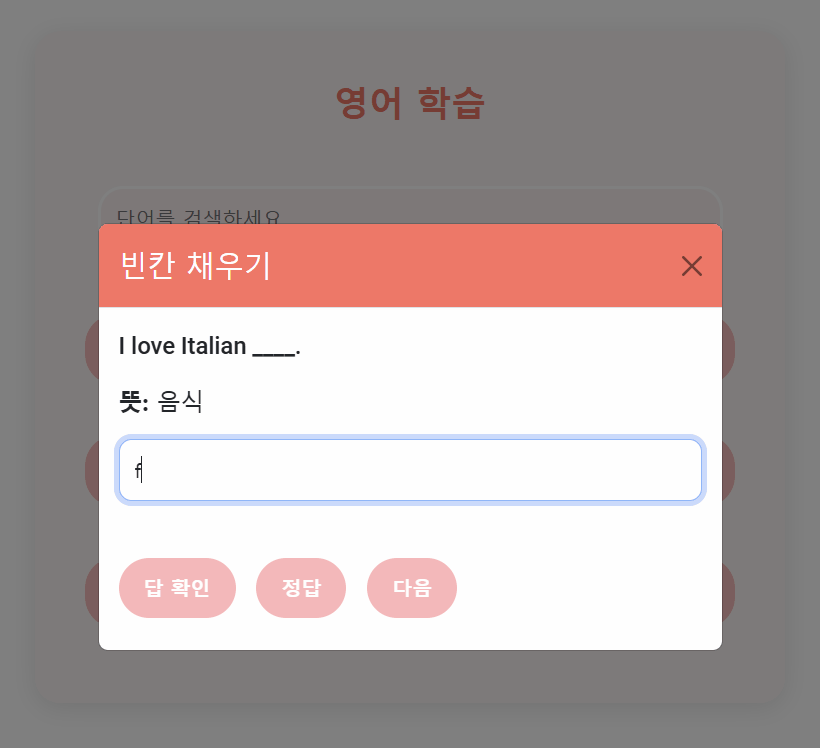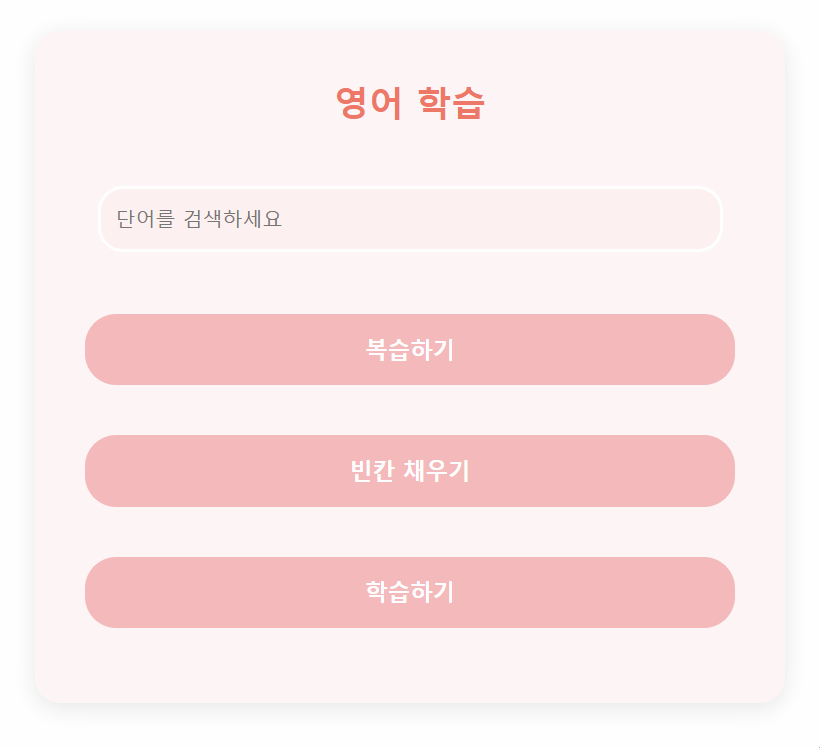
front는 ChatGPT를 통해 기본적인 HTML과 CSS 디자인을 구현하여 개발 시간을 절약했다.
프로젝트에서 가장 중요한 부분은 데이터 저장 및 성능 개선이다.
db는 중복을 피하기 위해 관계형 데이터베이스를 사용하고, 데이터 구조가 자주 변경될 일이 거의 없기 때문에 MySQL을 선택했다.
아래는 db 저장 방법을 정리한 글이다.
Flow
파일 첨부하기로 엑셀을 업로드하면 3개의 메소드로 나누어 db에 저장한다.
1. 단어 저장하기
2. 단어 뜻 저장하기
3. 예문, 예문 뜻, level 저장
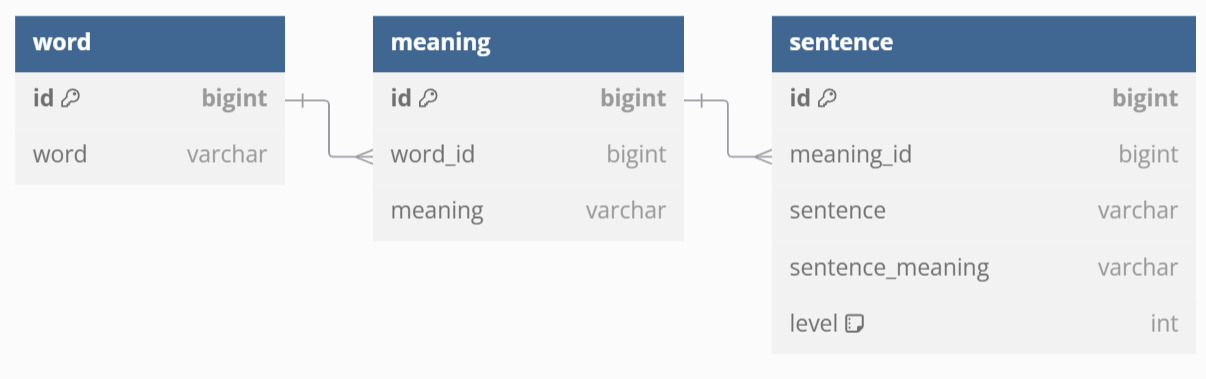
DB
AUTO_INCREMENT는 1부터 시작하도록 설정한다.
1
ALTER TABLE [Table 명] AUTO_INCREMENT=1;
단어 저장하기
중복 방지를 위해 단어는 UNIQUE 속성으로 저장했다.
1
2
3
4
5
CREATE TABLE word (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
word VARCHAR(50) NOT NULL,
UNIQUE KEY (word)
);
단어 뜻 저장하기
1
2
3
4
5
6
CREATE TABLE meaning (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
word_id BIGINT NOT NULL,
meaning VARCHAR(100) NOT NULL,
FOREIGN KEY (word_id) REFERENCES word (id) ON DELETE CASCADE
);
같은 뜻을 가진 단어가 여러 개 있을 수 있으므로, 단어 뜻은 UNIQUE 제약 조건을 설정하지 않았다.
*참고) unique key 생성 및 삭제
1
2
3
4
CREATE UNIQUE INDEX "인덱스 이름" ON "테이블명" ("컬럼명","컬럼명"); -- 생성
DROP INDEX "인덱스 이름" ON "테이블명"; -- 삭제
DROP INDEX user_number ON user; -- user 테이블의 user_number 인덱스 삭제
예문 저장하기
단어가 아닌 뜻을 fk로 잡은 이유는 특정 뜻에 해당하는 예문을 db에 저장하기 위해서다.
1
2
3
4
5
6
7
8
CREATE TABLE example (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
meaning_id BIGINT NOT NULL,
example varchar(400) NOT NULL,
example_meaning varchar(800) NOT NULL,
level INT,
FOREIGN KEY (meaning_id) REFERENCES meaning (id) ON DELETE CASCADE
);
예문마다 레벨을 설정해 초·중·고 수준에 따라 나눴으며 각각 0, 1, 2로 설정했다.
이 값을 int로 설정할 것인가 string으로 설정할 것인가에 대해 고민을 하다가
이 글을 보고 어떠한 계산을 하는 것이 아니기 때문에 string으로 설정했었다.
그런데 엑셀에서 숫자만 입력한 데이터는 string으로 값을 얻지 못해서 int로 저장했다.
Code
단어 저장하기
엑셀에서 가져온 단어 데이터를 Set 자료구조로 중복을 필터링한 뒤, DB에 저장한다.
Entity
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
@Entity
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED) // builder
public class Word {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(unique = true, nullable = false)
private String word;
@Builder
public Word(String word){
this.word = word;
}
// Set<Word> 중복 단어 필터링(equals와 hashCode 재정의)
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Word word1 = (Word) o;
return Objects.equals(word, word1.word);
}
@Override
public int hashCode() {
return Objects.hash(word);
}
}
Service
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
public void saveWord(MultipartFile file) throws IOException {
Workbook workbook = new XSSFWorkbook(file.getInputStream()); // workbook : 하나의 엑셀 파일을 의미
Sheet sheet = workbook.getSheetAt(0); // 첫번째 sheet
Set<Word> words = new HashSet<>();
Iterator<Row> rowIterator = sheet.iterator();
if (rowIterator.hasNext()) {
rowIterator.next(); // 첫 행(제목) 건너 뛰기
}
while (rowIterator.hasNext()) {
Row row = rowIterator.next();
Word word = Word.builder()
.word(row.getCell(0).getStringCellValue().strip())
.build();
words.add(word);
}
// DB에 저장(중복 try~catch)
try {
wordRepository.saveAll(words);
} catch (DataIntegrityViolationException e) {
// 중복 예외 처리
}
}
1차적으로 엑셀 파일에 중복이 있는지 Set을 사용하여 미리 제거후 db에 저장한다.
try-catch 블록을 통해 중복이 발생할 경우 SQLIntegrityConstraintViolationException 예외를 처리했다.
단어 뜻 저장하기
한 단어에 여러 뜻이 있을 경우를 고려하여 단어와 뜻을 분리했다.
Entity
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
@Entity
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Meaning {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@ManyToOne(fetch = LAZY, cascade = CascadeType.REMOVE) // ON DELETE CASCADE
@JsonIgnore
@JoinColumn(name="word_id")
private Word word;
@OneToMany(mappedBy = "meaning")
private List<Sentence> sentenceList = new ArrayList<>();
@Column(nullable = false)
private String meaning;
@Builder
private Meaning(Word word, String meaning){
this.word = word;
this.meaning = meaning;
word.getMeaningList().add(this);
}
public static Meaning createMeaning(Word word, String meaning){
return Meaning.builder()
.word(word)
.meaning(meaning)
.build();
}
}
word와 meaning을 일대다 매핑을 하고 연관관계 편의 메소드를 작성하던 도중
나는 builder 패턴으로 사용해서 연관관계 편의 메소드를 작성만 하고 service에서 사용은 안하고 있었다.
인프런 [1], [2] 글을 보고 참고하여 builder와 연관관계 편의 메소드를 작성해 사용했다.
Repository
단어와 뜻이 모두 존재할 경우 중복을 방지하기 위해 EXISTS를 사용하여 중복 체크를 수행했다.
JPQL에서는 count를 이용해 값 존재 여부를 확인한다.
단순히 중복이 있는지 확인하고 바로 종료하고 싶어서
jpql이 아닌 sql을 직접 정의하여 사용하는 방식인 NativeQuery를 사용했다.
1
2
3
4
5
6
7
8
public interface MeanRepository extends JpaRepository<Meaning, Long> {
@Query(nativeQuery = true, value = "SELECT EXISTS " +
"(SELECT 1 FROM Meaning m WHERE m.word_id = :wordId AND m.meaning = :meaning)")
int existsByWordAndMeaning(Long wordId, String meaning);
@Query(nativeQuery = true, value = "SELECT * FROM Meaning m WHERE m.word_id = :wordId AND m.meaning = :meaning LIMIT 1")
Optional<Meaning> findByMean(Long wordId, String meaning);
}
*limit를 사용할 수 있었지만 EXISTS가 더 빠른 성능을 보이므로 EXISTS를 활용했다.
*return 값을 Optional<Boolean>을 작성하여 isPresent()로 값이 있는지 체크하는 로직을 작성했지만
int로 return값을 작성한 것이 더 빠른 성능을 보여 int로 작성했다.
EXISTS 쿼리의 반환 결과는 0 또는 1 형태인 것을 MySQL Tutorial을 통해 확인했다.
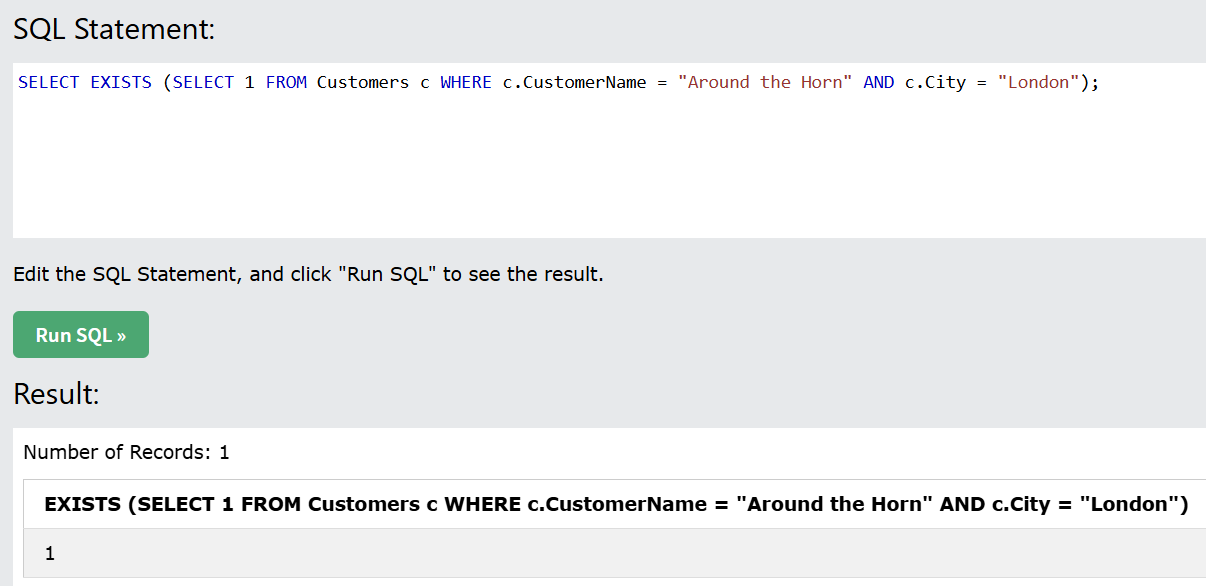
참고로 “SELECT EXISTS “ + 부분처럼 가독성을 위해 줄바꿈으로 작성할 경우
공백을 빼먹었는지 확인해준다. 공백을 빼먹으면 SQL 문법 오류가 뜬다.
JpaRepository<T, ID>
T: Entity 타입
ID: Entity의 기본 키 (Primary Key) 타입
Service
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
private static final Map<String, Long> wordIdMap = new HashMap<>();
public void saveMeaning(MultipartFile file) throws IOException {
Workbook workbook = new XSSFWorkbook(file.getInputStream());
Sheet sheet = workbook.getSheetAt(0); // 첫번째 sheet
MultiValueMap<String, String> map = new LinkedMultiValueMap<>(); // key 중복
Iterator<Row> rowIterator = sheet.iterator();
List<Meaning> list = new ArrayList<>();
if (rowIterator.hasNext()) {
rowIterator.next(); // 첫 행(제목) 건너 뛰기
}
while (rowIterator.hasNext()) {
Row row = rowIterator.next();
String wordText = row.getCell(0).getStringCellValue().strip();
String meaningText = row.getCell(1).getStringCellValue().strip();
// 해당 key에 해당하는 값 중복 체크 (1차 중복 체크 - 메모리)
map.putIfAbsent(wordText, new ArrayList<>());
if(!Objects.requireNonNull(map.get(wordText)).contains(meaningText)){
map.add(wordText,meaningText);
Word word = wordRepository.findByWord(wordText)
.orElseThrow(() -> new NoSuchElementException("Word not found: " + wordText));
wordIdMap.put(word.getWord(), word.getId()); // saveSentence()에서 db 조회 최소화
// word와 meaning이 같이 중복인 경우는 새로 추가하지 않음(2차 중복 체크 - DB)
int exists = meanRepository.existsByWordAndMeaning(word.getId(), meaningText);
if (exists==0) {
list.add(Meaning.createMeaning(word, meaningText));
}
}
}
// 일괄 저장
meanRepository.saveAll(list);
}
예문 저장하기
Service
단어에 해당하는 뜻에 해당하는 예문을 db에 저장한다.
map에는 단어와 예문을 저장한다.
- map에서 단어에 해당하는 예문이 없다면?
- map에 단어와 예문을 저장한다.
- Meaning 테이블에서 해당 단어에 해당하는 뜻을 가져온다.
(그냥 뜻을 가져와버리면 해당 단어가 아닌 다른 단어의 동일한 뜻을 가져와버릴 수 있다.) - 해당 단어의 뜻과 예문이 중복되어있는지 db에서 체크한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
public void saveSentence(MultipartFile file) throws IOException {
Workbook workbook = new XSSFWorkbook(file.getInputStream());
Sheet sheet = workbook.getSheetAt(0);
Iterator<Row> rowIterator = sheet.iterator();
List<Sentence> list = new ArrayList<>();
MultiValueMap<String, String> map = new LinkedMultiValueMap<>(); // key 중복
if (rowIterator.hasNext()) {
rowIterator.next(); // 첫 행(제목) 건너 뛰기
}
while (rowIterator.hasNext()) {
Row row = rowIterator.next();
String word = row.getCell(0).getStringCellValue().strip();
String meaningText = row.getCell(1).getStringCellValue().strip();
String sentence = row.getCell(2).getStringCellValue().strip();
String sentence_meaning = row.getCell(3).getStringCellValue();
int level = (int) row.getCell(4).getNumericCellValue();
map.putIfAbsent(word, new ArrayList<>());
if (!Objects.requireNonNull(map.get(word)).contains(sentence)) {
map.add(word, sentence);
Meaning meaning;
if (wordIdMap.get(word) != null) { // db 조회 최소화
meaning = meanRepository.findByMean(wordIdMap.get(word), meaningText).orElseThrow();
} else {
Word wordId = wordRepository.findByWord(word).orElseThrow();
meaning = meanRepository.findByMean(wordId.getId(), meaningText).orElseThrow();
}
int exists = sentenceRepository.existsByMeanAndSentence(meaning.getId(), sentence);
if (exists == 0) {
list.add(Sentence.createSentence(meaning, sentence, sentence_meaning, level));
}
}
}
// 일괄 저장
sentenceRepository.saveAll(list);
}
실제로 같은 뜻을 넣어두고 해당 단어에 맞는 예문이 저장된것을 확인했다.
REFERENCE