마지막 글 조회
마지막 글 조회 최적화
기존 파일의 마지막 글을 조회할 때 while문을 없애면 시간이 더 줄어질 수 있을 것 같아 코드를 수정 했다.
기존 코드는 아래와 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
try (RandomAccessFile randomAccessFile = new RandomAccessFile(file, "r")) {
long fileLength = file.length();
if (fileLength > 0) {
randomAccessFile.seek(fileLength);
long pointer = fileLength - 2;
while (pointer > 0) {
randomAccessFile.seek(pointer);
char c = (char) randomAccessFile.read();
if (c == '\n') {
break;
}
pointer--;
}
randomAccessFile.seek(pointer+1);
String line = randomAccessFile.readLine();
if (line == null || line.trim().isEmpty()) {
return null;
}
if (line.startsWith(",")) {
line = line.substring(1);
}
// 이하 동일
파일 저장 형식
{"roomId":"6d0a2b57","type":"JOINED","sender":"hello","message":"환영합니다.","adminChat":0,"userChat":0,"day":"9/21","time":"01:04"}
,{"roomId":"6d0a2b57","type":"TALK","sender":"hello","message":"123","adminChat":1,"userChat":0,"day":"9/21","time":"01:04"}
첫번째 줄만 쉼표(,)가 없고 마지막 줄은 항상 공백(줄바꿈)으로 끝나게 저장된다.
1차 수정
ReversedLinesFileReader를 적용했다.
implementation 'commons-io:commons-io:2.11.0'
1
2
3
4
5
6
7
8
9
10
11
try (ReversedLinesFileReader r = new ReversedLinesFileReader(file,StandardCharsets.UTF_8)) {
long fileLength = file.length();
if (fileLength > 0) {
String line = r.readLine();
if (line == null || line.trim().isEmpty()) {
return null;
}
if (line.startsWith(",")) {
line = line.substring(1);
}
// 이하 동일
이 글을 보고 거꾸로 읽는 것이 오히려 시간을 더 잡아먹을 수 있다는 걸 알게 되었다.
기존 코드와 차이가 얼마나 나는지 출력시켜봤다.(System.nanoTime())
- 기존 코드 : 7,457,800ns
- ReversedLinesFileReader 적용 코드 : 15,646,500ns
기존 코드가 오히려 더 빠르게 동작했다.
RandomAccessFile와 ReversedLinesFileReader
이 둘의 차이를 알고 싶어서 gpt로 찾아봤다.
RandomAccessFile
RandomAccessFile은 seek()를 통해 파일 포인터를 특정 위치로 바로 이동시키고 필요한 부분만 읽는다.
char 단위로 읽으면서 줄바꿈 문자(\n)를 찾아 byte 단위로 탐색한다.
ReversedLinesFileReader
일정한 크기로 나눈 블록을 메모리에 로드한 후 그 안에서 줄바꿈 문자(\n)를 찾는다.
한 번에 블록 단위로 읽기 때문에 블록 내에 줄바꿈 문자가 없을 경우 추가 블록을 읽어 다시 검색하는 과정을 반복한다.
여러 줄을 한꺼번에 읽는 경우에는 효율적이지만, 한 줄만 읽는 경우 오버헤드가 발생한다.
나는 파일의 끝에서 2번째 줄만 읽으려고 했기 때문에 RandomAccessFile가 더 빠르게 동작했던 것 같다.
*오버헤드란?
추가적인 작업이나 불필요한 처리가 개입되어 원래 소요 시간보다 더 많은 시간이 걸리는 것을 의미한다.
예를 들어 원래 5초면 끝날 작업이 추가적인 처리로 인해 7초가 걸린다면 2초가 오버헤드가 된다.
2차 수정
사용자에 따라 변화하는 값외의 고정된 값(byte)을 계산하여 최소 값인 145를 넣었다.
또한, 첫 줄만 있을 경우와 두 줄 이상의 경우 차이에 따라서도 동일하게 적용하기 위해서
줄바꿈(\n)이 아닌 { 문자를 기준으로 줄을 찾고 {부터 읽도록 수정했다.
위와 같이 적용하면서 아래 코드는 필요없어졌다.
1
2
3
if (line.startsWith(",")) {
line = line.substring(1);
}
또, 테스트를 해보다가 문제점을 발견했는데
첫번째 줄만 있는 경우 줄바꿈을 만나 종료하는게 아니라 {에서 종료를 하게 된다.
그러면서 pointer+1을 하다보니 {가 아닌 rommId의 r부터 해당 줄을 읽게 되어버렸다.
따라서 \n가 아닌 {를 만나면 즉시 종료한 후 {부터 줄을 읽게 했다.
최종 코드
1
2
3
4
5
6
7
8
9
10
11
12
if (fileLength > 145) {
randomAccessFile.seek(fileLength);
long pointer = fileLength - 145;
while (pointer > 0) {
randomAccessFile.seek(pointer);
char c = (char) randomAccessFile.read();
if (c == '{') {
break;
}
pointer--;
}
randomAccessFile.seek(pointer);
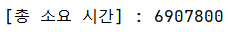
최종 성능 결과는 6,907,800 ns로 기존 7,457,800 ns에서 개선되었다.
REFERENCE