DB
*스프링 부트 핵심 가이드 책으로 스터디 진행
관련 글 : Controller, Service, Repository
ORM(Object Relational Mapping) : 객체 관계 매핑
객체지향 언어에서 의미하는 객체(클래스)와 RDB(관계형 데이터 베이스 : Relational Database)의 테이블을 자동으로 매핑하는 방법
( 영속화하는 것 )객체(자바 클래스)와 데이터베이스의 테이블 사이의 차이와 제약사항을 해결하는 역할
→ 클래스는 데이터베이스의 테이블과 매핑하기 위해 만들어진 것이 아니기 때문에 RDB 테이블과 어쩔 수 없는 불일치가 존재
장점
쿼리문 작성이 아닌 코드(메서드)로 데이터를 조작할 수 있다.
데이터베이스 쿼리를 객체지향적으로 조작할 수 있다.
재사용 및 유지보수가 편리하다.
데이터베이스에 대한 종속성이 줄어든다.
단점
ORM 만으로 온전한 서비스를 구현 하기에는 한계가 있다.
객체와 데이터베이스 관점의 불일치가 발생한다.
세분성(Granularity) : ORM의 자동 설계 방법에 따라 데이터베이스에 있는 테이블의 수와
애플리케이션의 엔티티(Entity)클래스의 수가 다른 경우가 생긴다. (보통 객체모델 > 관계형 모델)상속성(Inheritance) : RDBMS에는 상속이라는 개념이 없다.
식별성(Identity) : RDBMS는 기본키(primary key)로 동일성을 정의한다.
하지만 자바는 두 객체의 값이 같아도 다르다고 판단할 수 있다. (식별과 동일성의 문제)연관성(Association)
객체지향 언어는 객체를 참조 함으로써 연관성을 나타내지만
RDBMS 에서는 외래 키(foreign key)를 삽입 함으로써 연관성을 표시한다.탐색(Navigation)
자바와 RDBMS 는 어떤 값(객체)에 접근하는 방식이 다르다.
자바 에서는 특정 값에 접근하기 위해 객체 참조 같은 연결 수단을 활용한다.
이 방식은 객체를 연결하고 또 연결해서 접근하는 그래프 형태의 접근 방식이다.
(ex.member.getOranization().getAddress())반면 RDBMS 에서는 쿼리를 최소화하고 조인(JOIN)을 통해 여러 테이블을 로드 하고 값을 추출하는 접근 방식을 채택하고 있다.
JPA(Java Persistance API)
JPA는 자바에서 ORM 기술 표준으로 채택된 인터페이스
JPA가 실제로 동작하는 것이 아니라 동작 방법, 방식을 정리해둔 것
자바에서 사용할 ORM을 구현하기 위한 설계도면
JPA는 ORM을 사용하기 위한 인터페이스를 모아둔 것 ( = 기술 명세서 )
→ 단순 명세로 구현체가 없다.ORM 이 큰 개념이라면 JPA 는 더 구체화된 스펙을 포함한다.
특징
내부적으로 JDBC 를 사용한다. (데이터베이스에 접속할 수 있도록 하는 자바 API)
개발자 대신 SQL 을 생성하고 데이터베이스를 조작해 객체를 자동 매핑 하는 역할을 수행한다.
JPA 기반의 구현체 : EclipseLink, Hibernate, DataNucleus
JPA는 값을 갱신할 때 update 키워드를 사용하지 않는다.
영속성 컨텍스트를 활용해 값을 갱신하는데 find() method를 통해 db에서 값을 가져오면
가져온 객체가 영속성 컨텍스트에 추가된다.
영속성 컨텍스트가 유지되는 상황에서 객체의 값을 변경하고 다시 save()를 실행하면
JPA에서는 Dirty Check라고 하는 변경 감지를 수행한다.
Hibernate
자바의 ORM 프레임워크로 JPA가 정의하는 인터페이스를 구현하고 있는 JPA 구현체 중 하나
DB 의 데이터와 코드를 매핑 시켜주기 위한 프레임 워크
javax.persistence.EntityManager와 같은 인터페이스를 직접 구현한 라이브러리이다.
특징
- 생산성
- SQL 을 직접 사용하지 않고, 메서드 호출만으로 쿼리가 수행된다.
→ 단, 직접 SQL 을 작성하는 것보다는 성능상 좋지 않다.
→ 메서드 호출만으로 DB 데이터를 조작 하기에는 한계가 있다.
- SQL 을 직접 사용하지 않고, 메서드 호출만으로 쿼리가 수행된다.
- 유지보수
- SQL 반복 작업을 하지 않음으로 생산성이 높다. → 유지 보수 측면에서 좋다.
- 설정 파일에서 JPA 에게 어떤 DB 를 사용하고 있는지를 알려주기만 하면 얼마든지 DB 를 바꿀 수 있다.
- 패러다임 불일치 해결
- 상속, 연관 관계, 객체 그래프 탐색, 비교 등 객체와 관계형 DB와의 패러다임 불일치를 해결할 수 있다.
Spring Data JPA
CRUD 처리에 필요한 인터페이스를 제공
hibernate의 EntityManager를 직접 다루지 않고 Repository를 정의해 사용 → 내부적으로
EntityManager사용Spring Data JPA는 JPA를 추상화한 Repository를 제공하여 스프링이 적합한 쿼리를 동적으로 생성해 데이터베이스를 조작
JPA 를 편리하게 사용할 수 있도록 지원
Hibernate에서 자주 사용되는 기능을 더 쉽게 사용할 수 있게 구현한 라이브러리
Spring Data JPA는 Hibernate와 같은 JPA 구현체 필요
JpaRepository를 기반으로 쉽게 db를 사용할 수 있는 아키텍처를 제공
- JpaRepository를 상속받을 때는 대상 entity와 기본 값 타입을 지정해야한다.(
JpaRepository<Member, Long>)
- JpaRepository를 상속받을 때는 대상 entity와 기본 값 타입을 지정해야한다.(
영속성 컨텍스트
- 영속성 컨텍스트는 객체를 보관하는 기능을 수행한다.
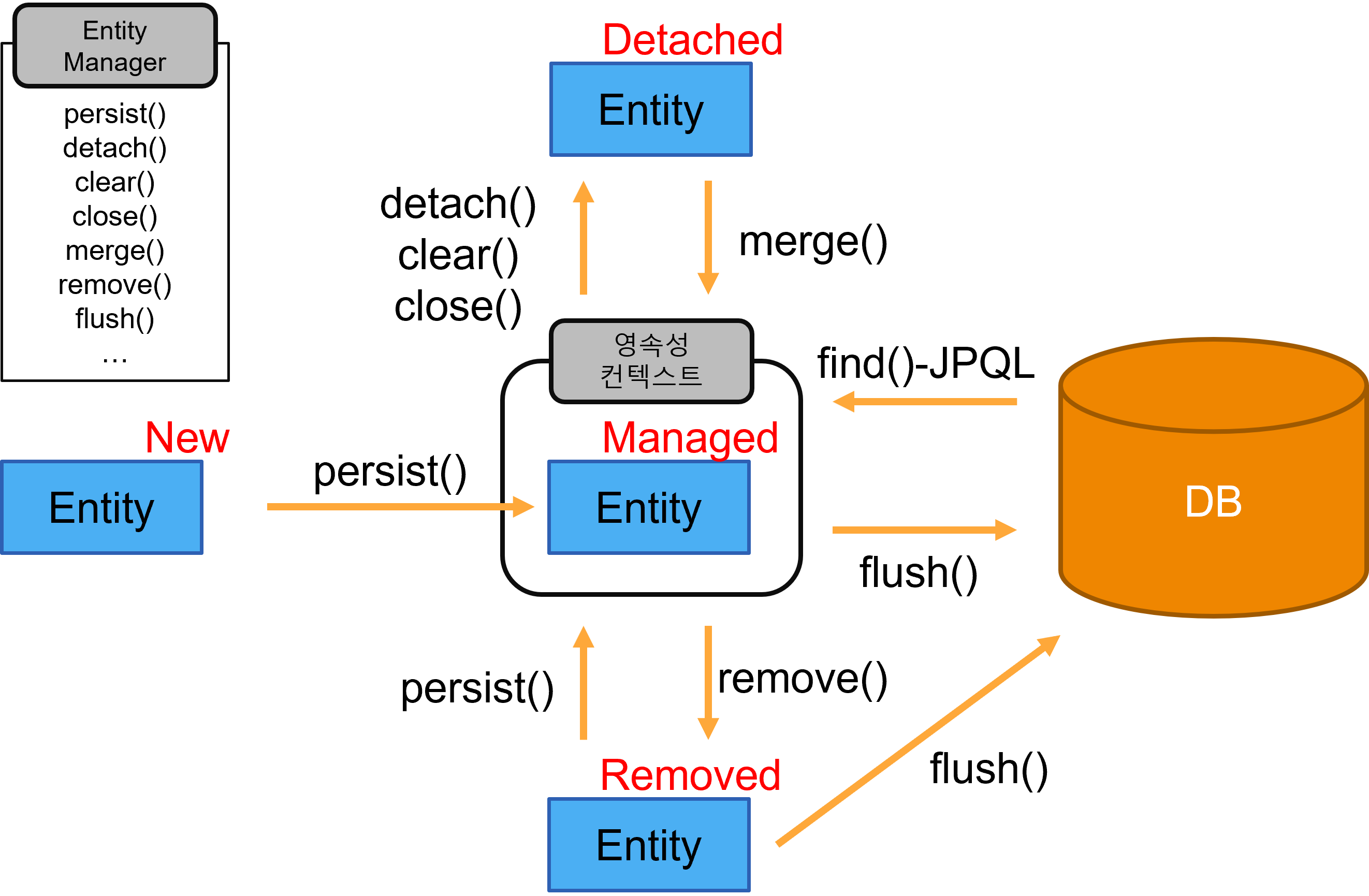
엔티티를 영구히 저장하는 환경
애플리케이션과 데이터베이스 사이에서 엔티티와 레코드의 괴리를 해소하는 기능과 객체를 보관하는 기능을 수행
엔티티 객체가 영속성 컨텍스트에 들어오면 JPA는 엔티티 객체의 매핑 정보를 데이터베이스에 반영하는 작업을 수행
엔티티 객체가 영속성 컨텍스트에 들어와 JPA의 관리 대상이 되는 시점부터는 해당 객체를 영속 객체(Persistence Object)라고 부른다.
세션단위의 생명주기를 가진다.
→ 데이터베이스에 접근하기 위한 세션이 생성되면 영속성 컨텍스트가 만들어지고, 세션이 종료되면 영속성 컨텍스트도 없어진다.엔티티 매니저는 이러한 일련의 과정에서 영속성 컨텍스트에 접근하기 위한 수단으로 사용된다.
→ 이것을 우리는 spring data jpa가 jpa를 가지고 해주고 있어서 편하게 해왔던 것이다.
엔티티 매니저 (Entity Manager)
엔티티를 관리하는 객체
DB에 접근해서 CRUD 작업을 수행한다.
Transaction 단위마다 EntityManager 생성
EntityManager가 생성되면 영속성 컨텍스트 생성
한 Transaction 안에서는 같은 영속성 컨텍스트 사용
Spring Data JPA 를 사용하면 Repository를 사용해서 데이터베이스에 접근한다.
→ 실제 내부 구현체인 SimpleJpaRepository 가Repository에서 엔티티 매니저를 사용한다.
@Transactional 어노테이션이 지정되어 있으면 method 내 작업을 마칠 경우 자동으로 flush() 를 실행한다.
EntityManager는 엔티티 매니저 팩토리( EntityManagerFactory )가 만든다.
엔티티 매니저 팩토리는 데이터베이스에 대응하는 객체로서 스프링 부트 에서는 자동 설정 기능이 있어
application.properties 에서 최소한의 설정만으로 동작하지만 하이버네이트에서는 설정파일을 구성하고 사용해야 한다.maven : persistence.xml
gradle : build.gradle, application.properties
☑️ EntityManagerFactory: 애플리케이션이 시작될 때 단 한 번 생성되며, 데이터베이스와의 연결을 관리하는 역할을 한다.
여러 개의 EntityManager를 생성할 때 기반이 되는 팩토리 역할을 한다.
☑️ EntityManager: 클라이언트가 원하는 요구에 따라 생성되고, 트랜잭션 범위 내에서 독립적으로 동작한다.
데이터베이스와의 상호작용을 위해 필요한 작업들을 수행하며, 엔티티들을 조회, 저장, 수정, 삭제할 수 있다.
☑️ 영속성 컨텍스트: EntityManager가 관리하는 핵심 개념으로, 엔티티들의 상태를 추적하고 관리한다.
1차 캐시를 가지고 있어 자주 사용되는 엔티티를 메모리에 보관하여 조회 성능을 향상시키고, 엔티티들의 동일성을 보장한다.
트랜잭션 범위 내에서 동작하며, 트랜잭션이 커밋되면 변경된 엔티티들이 데이터베이스에 동기화되고 롤백되면 변경 사항이 취소된다.
→ EntityManagerFactory는 한 번만 생성되고, EntityManager는 필요에 따라 생성되고 독립적으로 동작하며,
영속성 컨텍스트는 EntityManager가 관리하는 엔티티들의 상태를 추적하고 관리한다.
이러한 개념들을 활용하여 JPA를 효과적으로 사용할 수 있다.
Gradle 설정 예시
1
2
3
4
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
runtimeOnly 'mysql:mysql-connector-java'
}
1
2
3
4
5
6
7
8
9
10
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/test # jdbc:mysql://'DB-EndPoint':'Port'/'DBName'
spring.datasource.username= haedal
spring.datasource.password= 123456789
# SQL output
spring.jpa.properties.hibernate.format_sql=true
# show sql console
spring.jpa.show-sql=true
Hibernate 설정 시
엔티티 매니저 팩토리는 애플리케이션에 단 하나만 생성 되며, 모든 엔티티가 공유해서 사용한다.
엔티티 매니저 팩토리로 생성된 엔티티 매니저는 엔티티를 영속성 컨텍스트에 추가해서 영속 객체로 만드는 작업을 수행한다.
영속성 컨텍스트와 데이터베이스를 비교하면서 실제 데이터베이스를 대상으로 작업을 수행한다.
엔티티의 생명주기
비영속성(New) : 영속성 컨텍스트에 추가되지 않은 엔티티 객체의 상태를 의미
영속(Managed) : 영속성 컨텍스트에 의해 엔티티 객체가 관리되는 상태
준영속(Detached) : 영속성 컨텍스트에 의해 관리되던 엔티티 객체가 컨텍스트와 분리된 상태
삭제(Removed) : 데이터베이스에서 레코드를 삭제하기 위해 영속성 컨텍스트에 삭제요청을 한 상태
DataBase
테이블 자동 생성 application.properties 설정
spring.jpa.hibernate.ddl-auto= create : create 옵션은 해당하는 테이블이 있으면 DROP하고 새로 만들어 버린다.
*로컬 환경에서만 사용한다.
spring.jpa.show-sql=true : SQL이 보이도록 세팅
데이터 베이스 자동 조작 옵션
create : 기존 테이블을 지우고 새로 생성
create-drop : 애플리케이션을 종료하는 시점에 테이블을 지운다.
update : 실행될 객체를 검사해서 변경된 스키마를 갱신, 기존에 저장된 데이터는 유지
validate : update처럼 객체를 검사하지만 스키마는 건들지 않는다. (데이터베이스의 테이블 정보와 객체정보가 다른면 에러 발생)
none : ddl-auto 기능을 사용하지 않는다.
→ 운영 환경: create, create-drop, update (X) ➡️ validate, none (O)
→ 개발 환경: create, update (O)
Entity
Spring Data JPA를 사용해 데이터베이스에 테이블을 생성하기 위해 직접 쿼리를 작성할 필요가 없게 해준다.
데이터베이스에 쓰일 테이블과 칼럼을 정의하면 알아서 테이블을 생성 해준다.
엔티티 관련 기본 어노테이션
@Entity
클래스가 엔티티임을 명시하기 위한 어노테이션
해당 클래스의 인스턴스는 매핑되는 테이블에서 하나의 레코드를 의미한다.
@Entity가 붙은 클래스는 JPA가 관리 ➡️ JPA를 사용해서 DB 테이블과 매핑할 클래스는 @Entity를 꼭 붙여야만 매핑이 가능
주의사항
- 접근 제어자가 public 혹은 protected 인 기본 생성자가 필수
- final 클래스, enum, interface, inner 클래스에는 사용이 불가
@Enumerated를 사용하면 enum 클래스는 사용 가능하다. - 저장하려는 속성은 final 이면 안된다.
@Table(속성=?)
→ 엔티티와 매핑할 테이블을 지정
클래스의 이름과 테이블의 이름을 다르게 지정해야하는 경우가 아니면 필요X
속성
name : 매핑할 테이블 이름 지정
catalog : catalog 기능이 있는 데이터베이스에서 catalog를 매핑
schema : schema 기능이 있는 데이터베이스에서 schema를 매핑
uniqueConstraints (DDL) : DDL 생성 시에 유니크 제약조건을 만든다. 스키마 자동 생성 기능을 사용해서 DDL을 만들 때만 사용
@Id
테이블 기본 값 역할로 사용
모든 엔티티는 @Id 어노테이션이 필요하다.
@GeneratedValue
해당 필드의 값을 어떤 방식으로 자동으로 생성할지 결정할 때 사용
- GeneratedValue를 사용하지 않는 방식(직접 할당)
- 자체적으로 고유한 기본값을 생성할 경우 사용
- 내부에 정해진 규칙에 의해 기본값을 생성하고 식별자로 사용
- AUTO
- @GeneratedValue의 기본 설정값
- 기본값을 사용하는 데이터베이스에 맞게 자동 생성
- IDENTITY
- 기본값 생성을 데이터베이스에 위임
- 데이터베이스의
AUTO_INCREMENT를 사용해 기본값을 생성 (데이터베이스에 INSERT SQL 을 실행한 후에 엔티티의 식별자 값을 알 수 있다.)
- SEQUENCE
- @SequenceGenerator 어노테이션으로 식별자 생성기를 설정하고 이를 통해 값을 자동 주입 받는다.
- SequenceGenerator를 정의할 때는 name, SequenceGenerator, allocationSize를 활용
- @GeneratedValue에 생성기를 설정
- Table
- 어떤 DBMS를 사용하더라도 동일하게 동작하기를 원할 경우 사용
- @TableGenerator 어노테이션으로 테이블 정보를 설정
@Column
데이터베이스를 설정하는 어노테이션
별다른 설정을 하지 않을 예정이라면 필요X
name: 데이터베이스의 컬럼명을 설정nullable: 컬럼 값에 null 처리가 가능한지를 명시length: 데이터 최대 길이를 설정unique: 유니크로 설정
@Transient
엔티티 클래스에는 선언돼 있는 필드지만 데이터베이스에서는 필요 없을 경우 사용
출처
ddl-auto 옵션 관련 주의할 점!!!!!!!!!
[Spring Boot] JPA(Hibernate) 적용
스프링 부트 핵심 가이드