단어 학습하기
단어 학습하기
이 전에는 엑셀을 통해 db를 저장했다면 이제는 해당 db를 활용해 단어를 학습하는 기능을 구현했다.
전체코드는 eng에서 확인할 수 있다.
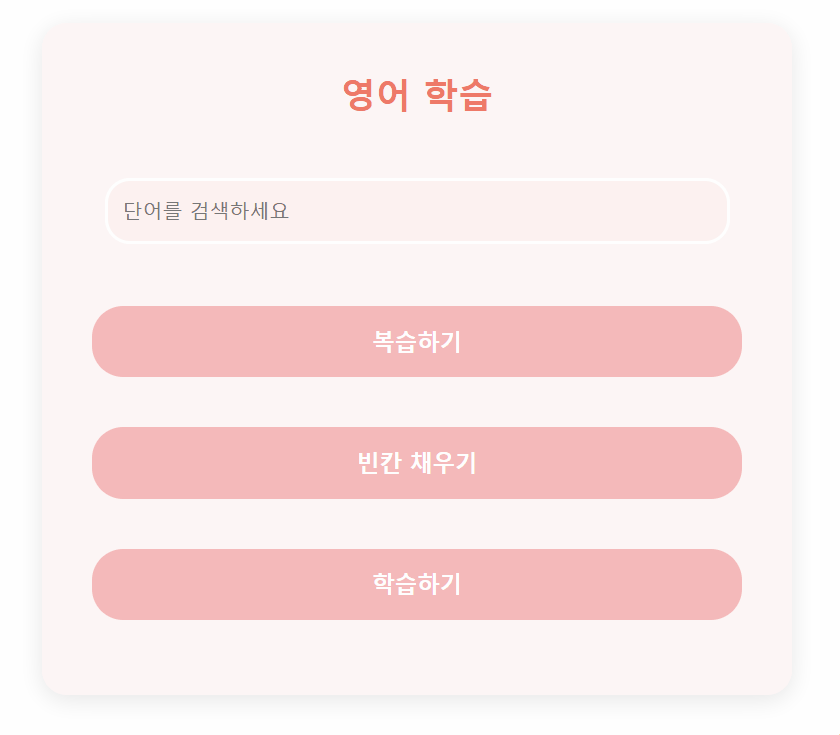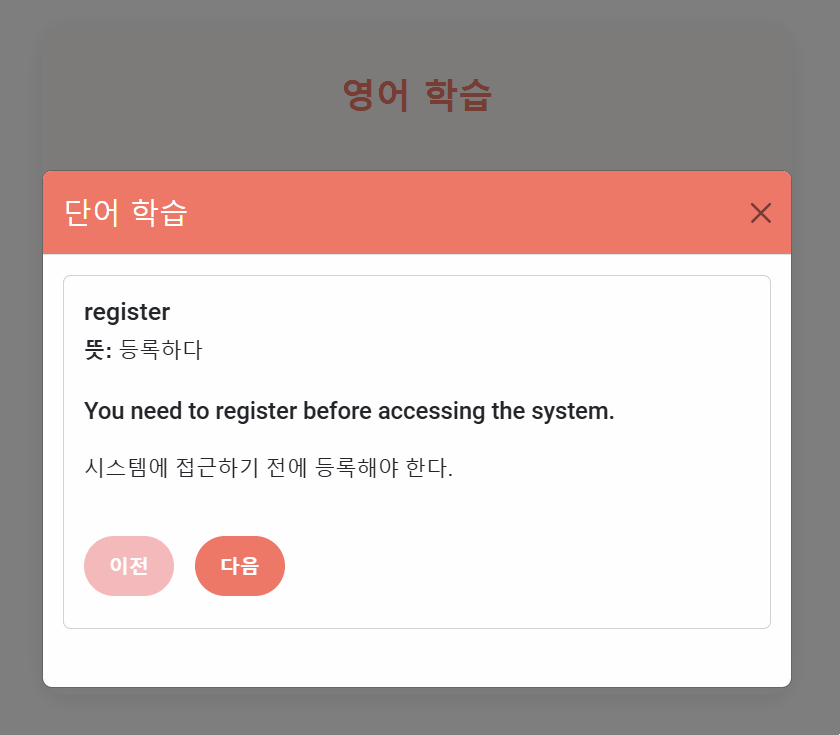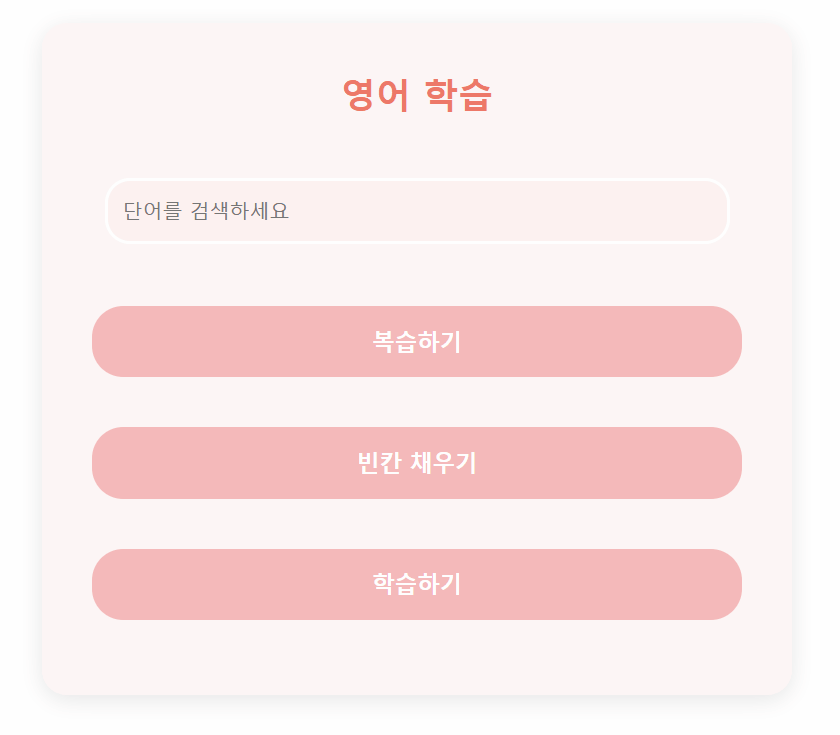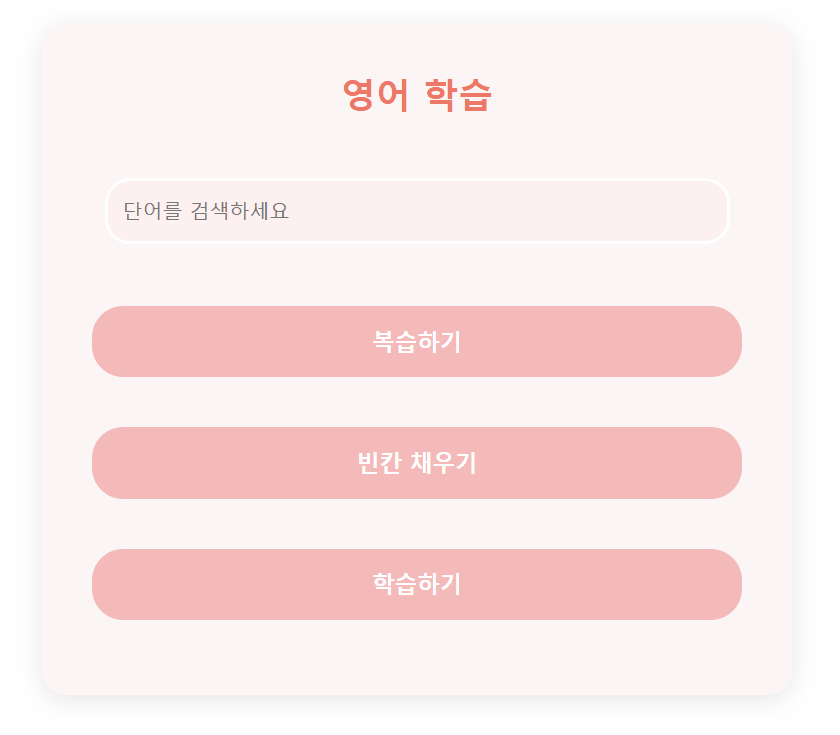
구현 동작 예시
주요 기능 구현 사항
1. 사용자가 학습하지 않은 단어 조회
2. 사용자가 학습한 단어 저장
DB 설계
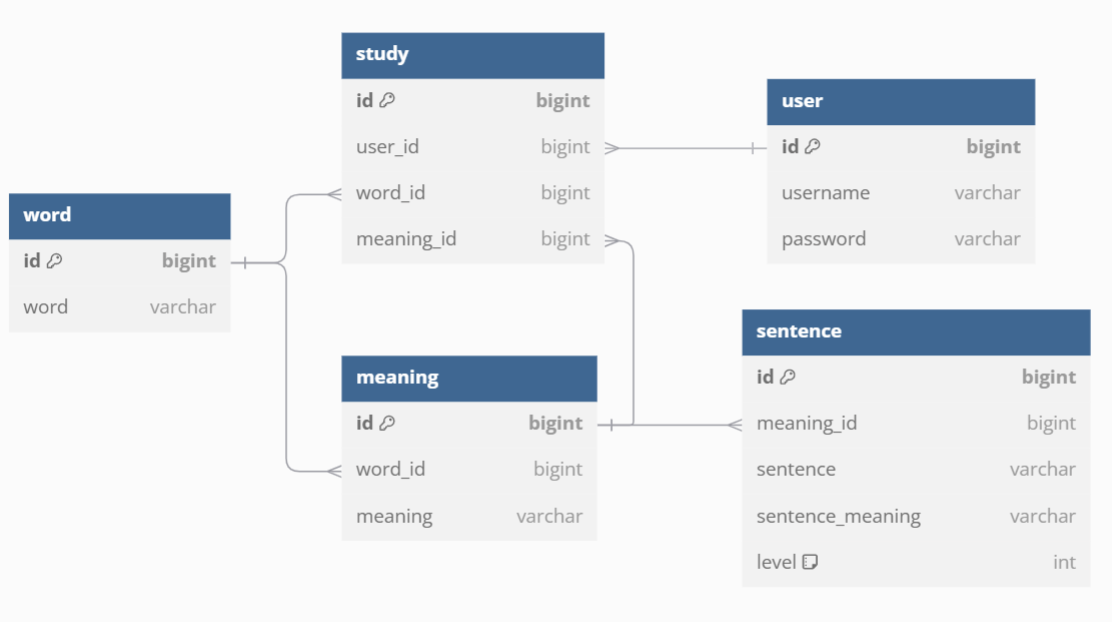
단어 학습 기능을 구현하기 위해 user_id와 word_id가 필요하다.
User와 Word는 다대다 관계(N:M)를 가지며 (사용자는 여러 단어를 학습할 수 있고 단어는 여러 사용자가 학습할 수 있다.)
사용자와 단어 간의 학습 기록을 저장하기 위해 중간 테이블인 Study를 추가했다.
관계 설정
- User - Study : 사용자는 여러 단어를 학습할 수 있다.
- Word - Study : 각 단어는 여러 사용자가 학습할 수 있다.
테이블 생성 과정
User
1
2
3
4
5
CREATE TABLE user(
id BIGINT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(30) NOT NULL,
password VARCHAR(50) NOT NULL
);
Study 테이블 생성
🔽 최종
1
2
3
4
5
6
7
8
9
10
CREATE TABLE study(
id BIGINT AUTO_INCREMENT PRIMARY KEY,
user_id BIGINT NOT NULL,
word_id BIGINT NOT NULL,
meaning_id BIGINT NOT NULL, -- 뜻(meaning)을 기준으로 학습 이력을 기록
FOREIGN KEY (user_id) REFERENCES user (id) ON DELETE CASCADE,
FOREIGN KEY (word_id) REFERENCES word (id) ON DELETE CASCADE,
FOREIGN KEY (meaning_id) REFERENCES meaning (id) ON DELETE CASCADE,
UNIQUE user_id (user_id, word_id, meaning_id) -- 특정 단어-뜻 중복 학습 방지
);
초기 버전
1
2
3
4
5
6
7
8
CREATE TABLE study(
id BIGINT AUTO_INCREMENT PRIMARY KEY,
user_id BIGINT NOT NULL,
word_id BIGINT NOT NULL,
FOREIGN KEY (user_id) REFERENCES user (id) ON DELETE CASCADE,
FOREIGN KEY (word_id) REFERENCES word (id) ON DELETE CASCADE,
UNIQUE (user_id, word_id) -- 중복 학습 방지
);
초기에는 단순히 user_id와 word_id만으로 유니크 제약 조건을 설정했으나
단어에 여러 뜻이 있는 경우를 고려하지 않아
이후 뜻(meaning) 기준으로 학습 이력을 관리하도록 meaning_id를 추가했다.
중복을 방지하기 위해 기존 유니크 조건을 user_id, word_id, meaning_id 조합으로 변경했다.
1
2
3
4
5
ALTER TABLE study
ADD COLUMN meaning_id BIGINT NOT NULL;
ALTER TABLE study
ADD FOREIGN KEY (meaning_id) REFERENCES meaning (id) ON DELETE CASCADE;
제약조건 확인
기존의 유니크 제약 조건 이름을 따로 설정하지 않아서 dbms가 자동으로 생성한 이름을 확인한다.
1
2
USE eng; -- USE [DB_NAME];
SHOW CREATE TABLE study; -- SHOW CREATE TABLE [TABLE_NAME];
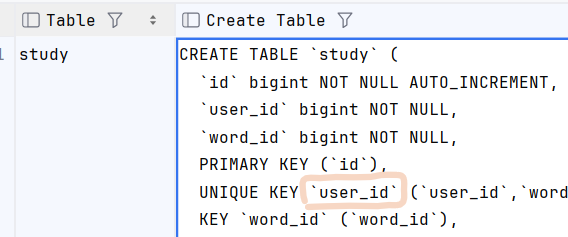
user_id 임을 확인해서 아래와 같이 실행했다.
1
2
3
ALTER TABLE study
DROP INDEX user_id,
ADD UNIQUE (user_id, word_id, meaning_id);
학습하지 않은 단어 조회
Entity
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
@Getter
@Entity
@Table( // 복합 unique key 설정
name = "study",
uniqueConstraints = @UniqueConstraint(columnNames = {"user_id", "word_id","meaning_id"})
)
public class Study {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private long id;
@ManyToOne(fetch = FetchType.LAZY, cascade = CascadeType.REMOVE)
@JoinColumn(name = "user_id")
private User user;
@ManyToOne(fetch = FetchType.LAZY, cascade = CascadeType.REMOVE)
@JoinColumn(name = "user_id")
private Word word;
@Builder
private Study(User user, Word word) {
this.user = user;
this.word = word;
}
public static Study createStudy(User user, Word word) {
return Study.builder()
.user(user)
.word(word)
.build();
}
}
user_id는 여러 study를 가질 수 있다. → 1:N 관계
💡다대다 관계에서 @ManyToMany를 사용하면 안 되는 이유
1. 카테시안 곱 문제
다대다 관계의 조인은 RDB에서 카테시안 곱을 발생시켜 예상하지 못한 쿼리가 발생할 수 있다.
2. 중간 테이블의 한계
JPA의 @ManyToMany 관계를 사용할 경우 자동으로 생성되는 중간 테이블은
두 테이블의 외래 키(a_id, b_id)만으로 구성된다.
이 때 중간 테이블은 연결된 각각의 테이블에 대한 키값을 가지고 있을 뿐
실무에서 필요한 여러 추가 정보를 포함 할 수 없다
3. 복합 키로 인한 중복 데이터 문제
중간 테이블에서 a_id + b_id 조합이 복합 기본 키(PK)이자 외래 키(FK) 역할을 한다.
예를 들어 a_id가 1이고 b_id가 2인 경우와 a_id가 1이고 b_id가 3인 경우
동일한 a_id에 대해 여러 b_id 값이 중복될 수 있다.
이로 인해 a_id 만으로 데이터를 구분할 수 없다. 그 반대도 마찬가지이다.
4. 데이터 무결성 문제
중복된 a_id, b_id 조합을 방지하기 어렵기 때문에 데이터의 무결성과 효율성에 문제가 생길 수 있다.
따라서 중간 테이블을 엔티티로 변환하여 1:N, 1:M 관계로 분리하는 것이 좋다.
1차 구현
Repository
1
2
3
4
5
// WordRepository
@Query(nativeQuery = true, value = "SELECT * FROM word w WHERE w.id NOT IN " +
"(SELECT s.word_id FROM study s WHERE s.user_id = :userId) " +
"ORDER BY w.id LIMIT 10")
List<Word> findByWordsForStudy(Long userId);
Study 테이블에서 사용자가 이미 학습한 단어의 word_id를 제외하고
Word 테이블에서 남은 단어를 id 기준으로 순서대로 10개 가져오도록 작성했다.
2차 수정 : Meaning을 기준으로 수정
1
2
3
4
5
6
7
// MeanRepository
@Query(nativeQuery = true, value = "SELECT m FROM meaning m " +
"WHERE m.id NOT IN ( " +
" SELECT s.meaning_id FROM study s WHERE s.user_id = :userId " +
") " +
"ORDER BY m.id ASC LIMIT 10")
List<Meaning> findByMeanForStudy(Long userId);
meaning_id를 기준으로 study 테이블에서 해당 사용자가 학습하지 않은 Meaning 데이터 10개를 가져온다.
해당 meaning에 연결된 word_id와 함께 list에 담긴다.
Service
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// 단어 가져오기
public List<StudyResponseDto> getStudyWord(String username){
User user = userRepository.findByUsername(username).orElseThrow(UserNotFoundException::new);
List<Meaning> result = meanRepository.findByMeanForStudy(user.getId());
List<StudyResponseDto> list = new ArrayList<>();
for(Meaning meaning : result){
Sentence sentence = sentenceRepository.findBySentence(meaning.getId()).orElseThrow(SentenceNotFoundException::new);
list.add(StudyResponseDto.of(
meaning.getWord().getWord(),
meaning.getMeaning(),
sentence.getSentence(),
sentence.getSentence_meaning(),
sentence.getLevel()
));
}
return list;
}
내가 원하는 흐름대로는 작성했으나
sentenceRepository.findBySentence(meaning.getId())를 반복적으로 호출하면 db에 여러 번 접근하게 되어서
Meaning과 Sentence를 함께 조회하기 위해 INNER JOIN을 사용했다.
3차 구현 : INNER JOIN 사용
LEFT JOIN보다 INNER JOIN이 성능 면에서 더 우수하며
Meaning(뜻)과 Sentence(예문) 둘 다 존재해야하므로 null을 방지하는 inner join을 사용했다.
1
2
3
4
5
6
7
8
9
10
// MeanRepository
@Query(nativeQuery = true, value =
"SELECT m.*, s.* " +
"FROM meaning m " +
"INNER JOIN sentence s ON m.id = s.meaning_id " +
"WHERE m.id NOT IN ( " +
" SELECT study.meaning_id FROM study WHERE study.user_id = :userId " +
") " +
"ORDER BY m.id LIMIT 10")
List<Object[]> findByMeanForStudyWithSentence(Long userId);
사용자가 학습하지 않은 meaning_id에 대해 meaning과 sentence의 교집합을 가져온다.
SELECT m.*, s.*: meaning과 sentence 테이블의 모든 컬럼을 각각 가져온다.FROM meaning m INNER JOIN sentence s ON m.id = s.meaning_id: meaning과 sentence를 조인하여 공통적인 값만 가져온다.WHERE m.id NOT IN (~): 사용자가 이미 학습한 meaning_id를 제외한 항목들만 가져온다.ORDER BY m.id LIMIT 10: meaning의 id값을 기준으로 정렬하고 상위 10개 결과만 반환한다.(ASC)
Service
return 값이 객체가 아닌 Meaning의 컬럼 값과 Sentence의 컬럼 값으로 return 되면서
Word(단어)를 알려면 또 다시 db조회를 해야했다.
1
2
3
4
5
6
7
8
9
10
11
12
public void getStudyWord(String username){
User user = userRepository.findByUsername(username).orElseThrow(UserNotFoundException::new);
List<Object[]> results = meanRepository.findByMeanForStudyWithSentence(user.getId());
for(Object[] result:results){
System.out.println("result[0] = " + result[0]);
System.out.println("result[1] = " + result[1]);
System.out.println("result[2] = " + result[2]);
System.out.println("result[3] = " + result[3]);
System.out.println("result[4] = " + result[4]);
System.out.println("result[5] = " + result[5]);
}
}
출력 예시)

4차 수정 : JPQL + Pageable
1
2
3
4
@Query("SELECT m, s FROM Meaning m JOIN Sentence s ON m.id = s.meaning.id " +
"WHERE m.id NOT IN (SELECT study.meaning.id FROM Study study WHERE study.user.id = :userId) " +
"ORDER BY m.id")
Page<Object[]> findByMeanForStudyWithSentence(Long userId, Pageable pageable);
nativeQuery 대신 JPQL을 사용하여 LIMIT 대신 페이징을 활용했다
JPQL은 인터페이스로 구현했을 때는 @Query을 사용한다.
콜론(:)을 사용해서 파라미터로 넘어온 값을 저장해준다.
Service
JPQL에서 LIMIT을 대신하기 위해 페이징을 사용했다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
public List<StudyResponseDto> getStudyWord(String username) {
User user = userRepository.findByUsername(username).orElseThrow(UserNotFoundException::new);
Pageable pageable = PageRequest.of(0, 10);
Page<Object[]> results = meanRepository.findByMeanForStudyWithSentence(user.getId(), pageable);
List<StudyResponseDto> list = new ArrayList<>();
for (Object[] result : results) {
Meaning meaning = (Meaning) result[0];
Sentence sentence = (Sentence) result[1];
list.add(StudyResponseDto.of(
meaning.getWord().getWord(),
meaning.getMeaning(),
sentence.getSentence(),
sentence.getSentence_meaning(),
sentence.getLevel()
));
}
return list;
}
Page: 페이징 결과 객체PageRequest: 실제로 페이징 객체를 만들 때 사용하는 클래스(Pageable의 구현체)PageRequest.of(page, 10): page는 조회할 페이지의 번호, 10은 한 페이지에 보여 줄 게시물의 개수
Pageable: 페이징 정보를 담는 인터페이스- page 번호, size(페이지당 데이터 개수), sort
실행하면 아래와 같이 front에서 받게 된다.

front
front에서는 단어 목록들을 받아서 localStorage에 저장한다.
첫번째와 마지막 단어를 구분하여 첫번째는 “이전” 버튼이 없으며 마지막 단어장에는 “다음” 버튼이 생기지 않게 했다.
모달 창을 중간에 닫고 다시 열면 마지막에 봤던 단어장이 띄워지며
이 때, 다시 서버에 요청을 해서 db를 조회하는 것이 아니라 localStorage에 있던 값을 받아 활용한다.
객체 저장할 때는 아래와 같이 작성해야한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
// 단어 목록들 저장
if(localStorage.getItem(username)){
cards = JSON.parse(localStorage.getItem(username)) // string → object로 변환
showStudyModal();
}else{
$.ajax({
// 생략
localStorage.setItem(username,JSON.stringify(response)); // string 형태로 저장
})
// 가장 마지막에 읽었던 단어 페이지 수 기억
let currentName = username+"page";
let currentCard = localStorage.getItem(currentName)?localStorage.getItem(currentName):0;
REFERENCE